How Does Optimism Work?
Optimism, as many of us know, is a Layer 2 project that offers a scalability solution for Ethereum. It uses optimistic rollup to solve Ethereum's scalability issue, and transactions occur off-chain on Optimism (Layer 2). However, Optimism must publish transaction data as calldata (Layer 1) on the mainnet for verification. ( Throughout the article, Layer 1 was used to represent the Ethereum main network; Layer 2 was used to represent Optimism. )
We can compare this situation to a restaurant kitchen. Optimism, like a sous chef; collects ingredients (i.e. processes), prepares them, and then hands them off to the head chef (main chain) to put the finishing touches on them. Thus, it makes transactions easier and more economical. So, if we ask why this scaling method is called optimism, it is because: All transactions processed at layer 2 or off-chain are assumed to be valid until a clear error or manipulation is found that indicates the opposite. That is, as long as everything goes well, transactions are considered valid.
If we have briefly understood Optimism, we can now go into the details of this “optimistic” chain and examine the basic workflow of Optimism:
- Users send transactions to the sequencer, and the sequencer processes these transactions on its own copy of the L2 chain.
- Once processed, the sequencer sends both the transaction data and the new L2 state root to L1.
- All L2 nodes then process the transaction on their own copies of the L2 chain.
- To ensure that the new state root sent to L1 is correct, validator nodes compare the new state roots with the state root sent by the sequencer.
- If there is a difference, the “proof of fraud” process begins and the change of status is deemed invalid.
- If the result of the fraud proof does not match the status root sent by the sequencer, the sequencer's initial deposit is deducted. The state roots after this operation are deleted and the sequencer is forced to recompute these missing state roots correctly.
- After the latest sequencer role was decentralized; If the sequencer's coverage is interrupted, a new sequencer is appointed. Thus, the reliability and continuity of the system is ensured.
Steps 1–4 of the workflow. You can review the steps in the visual.
There are two types of operations important for this system:
- L2 transactions between two addresses on the L2 chain
- Cross-chain transactions occurring between L1 and L2 chains
First, let's explain how L2 transactions between two addresses work:
- Users send their transactions to the sorter node.
- The sequencer adds valid transactions to the L2 chain. Each L2 block contains only one transaction.
- After adding a few transactions, the sequencer sends these transactions to a smart contract in L1. This contract stores transaction data and new state roots of the L2 chain.
- Once the transaction data is stored in L1, validator nodes include this transaction in their copy of the L2 chain.
- If the sequencer blocks a particular user, the user can view the transaction data himself and the sequencer has to process this transaction within a certain period of time. Otherwise, the sequencer's warranty may be terminated.
- Additionally, validators can synchronize not only to L1 but also from L2. This reduces latency but does not guarantee whether it will be sent to L1.
Second, let's examine the cross-transactions between L1 and L2 chains:
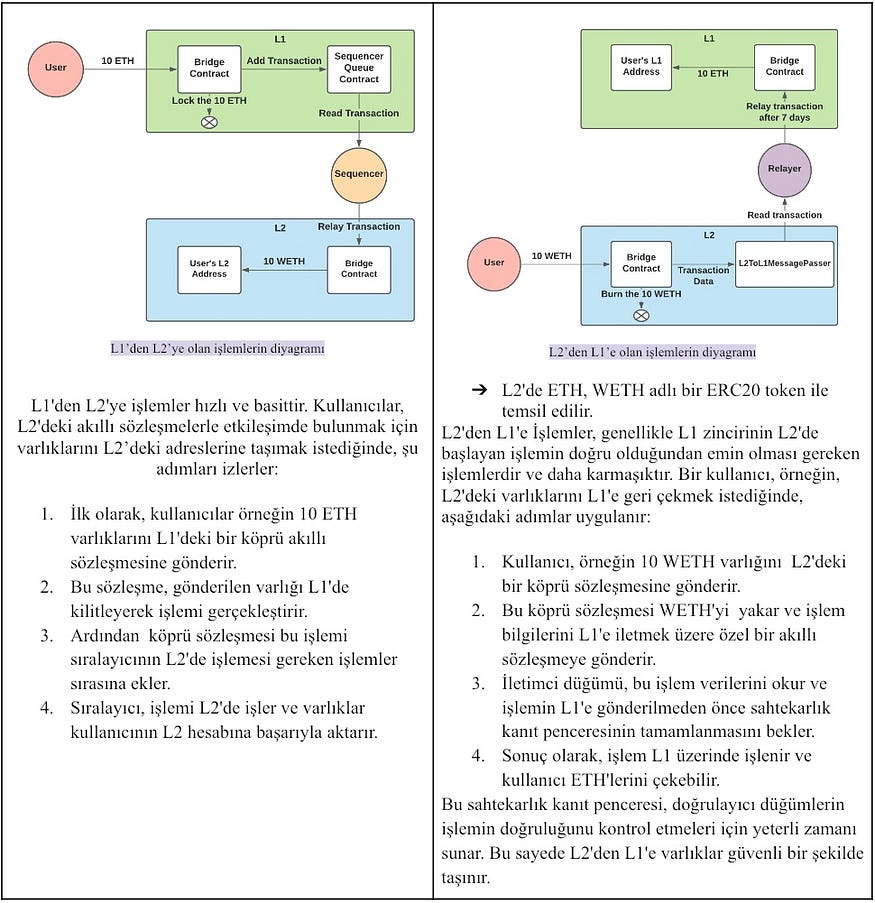 Storing Transaction and State Root in L1
Storing Transaction and State Root in L1
Since the transaction data and the resulting state root for each transaction must be stored in L1, minimizing the size of this data is very important to reduce the storage costs of the system. This is where "rollups" come into play.
Let's explain how the data for each L2 transaction is stored in L1:
- The sequencer takes the call data of a number of consecutive L2 operations and combines them into a single stack.
- The sequencer sends this batch of transactions to a smart contract known as “CanonicalTransactionChain”.
- Next, the smart contract hashes the call data of each transaction and creates a merkle tree from these hashes.
- CanonicalTransactionChain takes the merkle root of this group and sends it to a smart contract for storage.
You can examine the storage of L2 call data in L1 in this image.
So how does Optimism deal with security risks?
As it is known, although there are various priorities, "security" is one of the most important criteria in a blockchain project. At this point, Optimism uses the powerful components of Ethereum. These components include “L2Geth” (Ethereum's official client) and “EVM” (Ethereum Virtual Machine). Thus, Optimism provides a secure environment based on the well-audited security standards that these components already have. OVM (Optimism Virtual Machine) processes transactions in Ethereum in the same way as EVM, only moving these transactions off-chain and then sending only a very small amount of data back to the Ethereum main chain. This speeds up transactions and reduces transaction fees. EVM, on the other hand, verifies each transaction on the main chain.
As a result, OVM interacts with EVM to speed up Ethereum transactions and reduce transaction costs, providing security as well as a scaled and more efficient experience.
However, when we say “security” in Optimism, Fraud Proofs comes to mind. Fraud evidence is a vital mechanism for the security of the Optimism system. In fact, as I mentioned in the middle of the article, if a sequencer in Optimism tries to send a misleading state root to L1, this is a process in which the validator node comes into play. Then, the validator node initiates the fraud proof and performs the relevant L2 operation on L1, and if the result of the fraud proof is different compared to the state root sent by the sequencer to L1, the sequencer's loyalty letter is truncated, the state roots after that transaction are deleted and recalculated. OVM (Optimistic Virtual Machine) is used in Optimism to handle these fraud proof operations. This OVM ensures that transactions can be replayed on L1 and L2 chains with the same result. This makes it easier for validators to create proofs of fraud and replay transactions on L1.
If everything is considered correct, if we ask how the system works in case of fraud:
In Optimistic rollup, each node has a 7-day right of objection as a security measure regarding the data sent to the main network. If a single honest node on the L2 network objects, the person who sent false data is penalized and the honest node's data is accepted. This arrangement is used to ensure reliability and verification in the system. This 7-day period does not increase as the data held in the system increases, because after the objection window is opened, only the Merkle Tree of the objected transfer is examined, not the entire rollup.
In conclusion, if we understand the functioning and why should we use Optimism?, what is the advantage it offers us? Let's give a short answer to the question:
Optimism and optimistic rollups greatly increase the scalability of the Ethereum network, thereby reducing gas costs by keeping throughput constant. Ethereum processes every full node in its network, and since the network contains a large number of nodes, computation becomes very costly. In contrast, with Optimism, transactions are processed only by a select group of sorters and validators. Thus, while the computation of each transaction is moved out of L1, the transaction call data remains in L1. This frees up a lot of space in L1 and allows more operations to be performed. So with Optimism, by having larger capacity, there is less competition to add a transaction to a block and gas costs are reduced.Cryptocurrencies
1 Read
0 Wow
0 Meh
Medicine










![[ℕ𝕖𝕧𝕖𝕣] 𝕊𝕖𝕝𝕝 𝕐𝕠𝕦𝕣 𝔹𝕚𝕥𝕔𝕠𝕚𝕟 - And Now What.... Pray To The God Of Hopium?](https://cdn.bulbapp.io/frontend/images/79e7827b-c644-4853-b048-a9601a8a8da7/1)













![[LIVE] Engage2Earn: auspol follower rush](https://cdn.bulbapp.io/frontend/images/c1a761de-5ce9-4e9b-b5b3-dc009e60bfa8/1)




