Stochastic Gradient Descent: Math and Python CodeDeep Dive on Stochastic Gradient Descent. Algorith

Introduction
The image above is not just an appealing visual that drew you to this article (despite its length), but it also represents a potential journey of the SGD algorithm in search of a global minimum. In this journey, it navigates rocky paths where the height symbolizes the loss. If this doesn’t sound clear now, don’t worry, it will be by the end of this article.
Index:
· 1: Understanding the Basics
∘ 1.1: What is Gradient Descent
∘ 1.2: The ‘Stochastic’ in Stochastic Gradient Descent
· 2: The Mechanics of SGD
∘ 2.1: The Algorithm Explained
∘ 2.2: Understanding Learning Rate
· 3: SGD in Practice
∘ 3.1: Implementing SGD in Machine Learning Models
∘ 3.2: SGD in Sci-kit Learn and Tensorflow
· 4: Advantages and Challenges
∘ 4.1: Why Choose SGD?
∘ 4.2: Overcoming Challenges in SGD
· 5: Beyond Basic SGD
∘ 5.1: Variants of SGD
∘ 5.2: Future of SGD
· Conclusion
1: Understanding the Basics
1.1: What is Gradient Descent
Image by DALL-E-2
In machine learning , Gradient Descent is a star player. It’s an optimization algorithm used to minimize a function by iteratively moving towards the steepest descent as defined by the negative of the gradient. Like in the picture, imagine you’re at the top of a mountain, and your goal is to reach the lowest point. Gradient Descent helps you find the best path down the hill.
The beauty of Gradient Descent is its simplicity and elegance. Here’s how it works, you start with a random point on the function you’re trying to minimize, for example a random starting point on the mountain. Then, you calculate the gradient (slope) of the function at that point. In the mountain analogy, this is like looking around you to find the steepest slope. Once you know the direction, you take a step downhill in that direction, and then you calculate the gradient again. Repeat this process until you reach the bottom.
The size of each step is determined by the learning rate. However, if the learning rate is too small, it might take a long time to reach the bottom. If it’s too large, you might overshoot the lowest point. Finding the right balance is key to the success of the algorithm.
One of the most appealing aspects of Gradient Descent is its generality. It can be applied to almost any function, especially those where an analytical solution is not feasible. This makes it incredibly versatile in solving various types of problems in machine learning, from simple linear regression to complex neural networks.
1.2: The ‘Stochastic’ in Stochastic Gradient Descent
Stochastic Gradient Descent (SGD) adds a twist to the traditional gradient descent approach. The term ‘stochastic’ refers to a system or process that is linked with a random probability. Therefore, this randomness is introduced in the way the gradient is calculated, which significantly alters its behavior and efficiency compared to standard gradient descent.
In traditional batch gradient descent, you calculate the gradient of the loss function with respect to the parameters for the entire training set. As you can imagine, for large datasets, this can be quite computationally intensive and time-consuming. This is where SGD comes into play. Instead of using the entire dataset to calculate the gradient, SGD randomly selects just one data point (or a few data points) to compute the gradient in each iteration.
Think of this process as if you were again descending a mountain, but this time in thick fog with limited visibility. Rather than viewing the entire landscape to decide your next step, you make your decision based on where your foot lands next. This step is small and random, but it’s repeated many times, each time adjusting your path slightly in response to the immediate terrain under your feet.
This stochastic nature of the algorithm provides several benefits:
- Speed: By using only a small subset of data at a time, SGD can make rapid progress in reducing the loss, especially for large datasets.
- Escape from Local Minima: The randomness helps SGD to potentially escape local minima, a common problem in complex optimization problems.
- Online Learning: SGD is well-suited for online learning, where the model needs to be updated as new data comes in, due to its ability to update the model incrementally.
However, the stochastic nature also introduces variability in the path to convergence. The algorithm doesn’t smoothly descend towards the minimum; rather, it takes a more zigzag path, which can sometimes make the convergence process appear erratic.
2: The Mechanics of SGD
2.1: The Algorithm Explained
Stochastic Gradient Descent (SGD) might sound complex, but its algorithm is quite straightforward when broken down. Here’s a step-by-step guide to understanding how SGD works:
Initialization (Step 1)
First, you initialize the parameters (weights) of your model. This can be done randomly or by some other initialization technique. The starting point for SGD is crucial as it influences the path the algorithm will take.
Random Selection (Step 2)
In each iteration of the training process, SGD randomly selects a single data point (or a small batch of data points) from the entire dataset. This randomness is what makes it ‘stochastic’.
Compute the Gradient (Step 3)
Calculate the gradient of the loss function, but only for the randomly selected data point(s). The gradient is a vector that points in the direction of the steepest increase of the loss function. In the context of SGD, it tells you how to tweak the parameters to make the model more accurate for that particular data point.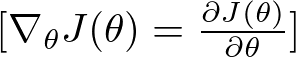 Gradient Formula
Gradient Formula
Here, ∇θJ(θ) represents the gradient of the loss function J(θ) with respect to the parameters θ. This gradient is a vector of partial derivatives, where each component of the vector is the partial derivative of the loss function with respect to the corresponding parameter in θ.
Update the Parameters (Step 4)
Adjust the model parameters in the opposite direction of the gradient. Here’s where the learning rate η plays a crucial role. The formula for updating each parameter is: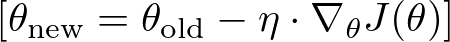 where:
where:
- θnew represents the updated parameters.
- θold represents the current parameters before the update.
- η is the learning rate, a positive scalar determining the size of the step in the direction of the negative gradient.
- ∇θJ(θ) is the gradient of the loss function J(θ) with respect to the parameters θ.
The learning rate determines the size of the steps you take towards the minimum. If it’s too small, the algorithm will be slow; if it’s too large, you might overshoot the minimum.
Repeat until convergence (Step 5)
Repeat steps 2 to 4 for a set number of iterations or until the model performance stops improving. Each iteration provides a slightly updated model.
Ideally, after many iterations, SGD converges to a set of parameters that minimize the loss function, although due to its stochastic nature, the path to convergence is not as smooth and may oscillate around the minimum.
2.2: Understanding Learning Rate
One of the most crucial hyperparameters in the Stochastic Gradient Descent (SGD) algorithm is the learning rate. This parameter can significantly impact the performance and convergence of the model. Understanding and choosing the right learning rate is a vital step in effectively employing SGD.
What is Learning Rate?
At this point you should have an idea of what learning rate is, but let’s better define it for clarity. The learning rate in SGD determines the size of the steps the algorithm takes towards the minimum of the loss function. It’s a scalar that scales the gradient, dictating how much the weights in the model should be adjusted during each update. If you visualize the loss function as a valley, the learning rate decides how big a step you take with each iteration as you walk down the valley.
Too High Learning Rate
If the learning rate is too high, the steps taken might be too large. This can lead to overshooting the minimum, causing the algorithm to diverge or oscillate wildly without finding a stable point.
Think of it as taking leaps in the valley and possibly jumping over the lowest point back and forth.
Too Low Learning Rate
On the other hand, a very low learning rate leads to extremely small steps. While this might sound safe, it significantly slows down the convergence process.
In a worst-case scenario, the algorithm might get stuck in a local minimum or even stop improving before reaching the minimum.
Imagine moving so slowly down the valley that you either get stuck or it takes an impractically long time to reach the bottom.
Finding the Right Balance
The ideal learning rate is neither too high nor too low but strikes a balance, allowing the algorithm to converge efficiently to the global minimum.
Typically, the learning rate is chosen through experimentation and is often set to decrease over time. This approach is called learning rate annealing or scheduling.
Learning Rate Scheduling
Learning rate scheduling involves adjusting the learning rate over time. Common strategies include:
- Time-Based Decay: The learning rate decreases over each update.
- Step Decay: Reduce the learning rate by some factor after a certain number of epochs.
- Exponential Decay: Decrease the learning rate exponentially.
- Adaptive Learning Rate: Methods like AdaGrad, RMSProp, and Adam adjust the learning rate automatically during training.
3: SGD in Practice
3.1: Implementing SGD in Machine Learning Models
Link to the full code (Jupyter Notebook):
models-from-scratch-python/Stochastic Gradient Descent/demo.ipynb at main ·…
Repo where I recreate some popular machine learning models from scratch in Python …
github.com
Implementing Stochastic Gradient Descent (SGD) in machine learning models is a practical step that brings the theoretical aspects of the algorithm into real-world application. This section will guide you through the basic implementation of SGD and provide tips for integrating it into machine learning workflows.
Now let’s consider a simple case of SGD applied to Linear Regression:
class SGDRegressor:
def __init__(self, learning_rate=0.01, epochs=100, batch_size=1, reg=None, reg_param=0.0):
"""
Constructor for the SGDRegressor.
Parameters:
learning_rate (float): The step size used in each update.
epochs (int): Number of passes over the training dataset.
batch_size (int): Number of samples to be used in each batch.
reg (str): Type of regularization ('l1' or 'l2'); None if no regularization.
reg_param (float): Regularization parameter.
The weights and bias are initialized as None and will be set during the fit method.
"""
self.learning_rate = learning_rate
self.epochs = epochs
self.batch_size = batch_size
self.reg = reg
self.reg_param = reg_param
self.weights = None
self.bias = None
def fit(self, X, y):
"""
Fits the SGDRegressor to the training data.
Parameters:
X (numpy.ndarray): Training data, shape (m_samples, n_features).
y (numpy.ndarray): Target values, shape (m_samples,).
This method initializes the weights and bias, and then updates them over a number of epochs.
"""
m, n = X.shape # m is number of samples, n is number of features
self.weights = np.zeros(n)
self.bias = 0
for _ in range(self.epochs):
indices = np.random.permutation(m)
X_shuffled = X[indices]
y_shuffled = y[indices]
for i in range(0, m, self.batch_size):
X_batch = X_shuffled[i:i+self.batch_size]
y_batch = y_shuffled[i:i+self.batch_size]
gradient_w = -2 * np.dot(X_batch.T, (y_batch - np.dot(X_batch, self.weights) - self.bias)) / self.batch_size
gradient_b = -2 * np.sum(y_batch - np.dot(X_batch, self.weights) - self.bias) / self.batch_size
if self.reg == 'l1':
gradient_w += self.reg_param * np.sign(self.weights)
elif self.reg == 'l2':
gradient_w += self.reg_param * self.weights
self.weights -= self.learning_rate * gradient_w
self.bias -= self.learning_rate * gradient_b
def predict(self, X):
"""
Predicts the target values using the linear model.
Parameters:
X (numpy.ndarray): Data for which to predict target values.
Returns:
numpy.ndarray: Predicted target values.
"""
return np.dot(X, self.weights) + self.bias
def compute_loss(self, X, y):
"""
Computes the loss of the model.
Parameters:
X (numpy.ndarray): The input data.
y (numpy.ndarray): The true target values.
Returns:
float: The computed loss value.
"""
return (np.mean((y - self.predict(X)) ** 2) + self._get_regularization_loss()) ** 0.5
def _get_regularization_loss(self):
"""
Computes the regularization loss based on the regularization type.
Returns:
float: The regularization loss.
"""
if self.reg == 'l1':
return self.reg_param * np.sum(np.abs(self.weights))
elif self.reg == 'l2':
return self.reg_param * np.sum(self.weights ** 2)
else:
return 0
def get_weights(self):
"""
Returns the weights of the model.
Returns:
numpy.ndarray: The weights of the linear model.
"""
return self.weightsLet’s break it down into smaller steps:
Initialization (Step 1)
def __init__(self, learning_rate=0.01, epochs=100, batch_size=1, reg=None, reg_param=0.0):
self.learning_rate = learning_rate
self.epochs = epochs
self.batch_size = batch_size
self.reg = reg
self.reg_param = reg_param
self.weights = None
self.bias = NoneThe constructor (__init__ method) initializes the SGDRegressor with several parameters:
learning_rate: The step size used in updating the model.epochs: The number of passes over the entire dataset.batch_size: The number of samples used in each batch for SGD.reg: The type of regularization (either 'l1' or 'l2';Noneif no regularization is used).reg_param: The regularization parameter.weightsandbiasare set toNoneinitially and will be initialized in thefitmethod.
Fit the Model(Step 2)
def fit(self, X, y):
m, n = X.shape # m is number of samples, n is number of features
self.weights = np.zeros(n)
self.bias = 0
for _ in range(self.epochs):
indices = np.random.permutation(m)
X_shuffled = X[indices]
y_shuffled = y[indices]
for i in range(0, m, self.batch_size):
X_batch = X_shuffled[i:i+self.batch_size]
y_batch = y_shuffled[i:i+self.batch_size]
gradient_w = -2 * np.dot(X_batch.T, (y_batch - np.dot(X_batch, self.weights) - self.bias)) / self.batch_size
gradient_b = -2 * np.sum(y_batch - np.dot(X_batch, self.weights) - self.bias) / self.batch_size
if self.reg == 'l1':
gradient_w += self.reg_param * np.sign(self.weights)
elif self.reg == 'l2':
gradient_w += self.reg_param * self.weights
self.weights -= self.learning_rate * gradient_w
self.bias -= self.learning_rate * gradient_bThis method fits the model to the training data. It starts by initializing weights as a zero vector of length n (number of features) and bias to zero. The model’s parameters are updated over a number of epochs through SGD.
Random Selection and Batches(Step 3)
for _ in range(self.epochs):
indices = np.random.permutation(m)
X_shuffled = X[indices]
y_shuffled = y[indices]In each epoch, the data is shuffled, and batches are created to update the model parameters using SGD.
Compute the Gradient and Update the parameters (Step 4)
gradient_w = -2 * np.dot(X_batch.T, (y_batch - np.dot(X_batch, self.weights) - self.bias)) / self.batch_size gradient_b = -2 * np.sum(y_batch - np.dot(X_batch, self.weights) - self.bias) / self.batch_size
Gradients for weights and bias are computed in each batch. These are then used to update the model’s weights and bias. If regularization is used, it’s also included in the gradient calculation.
Repeat and converge (Step 5)
def predict(self, X):
return np.dot(X, self.weights) + self.biasThe predict method calculates the predicted target values using the learned linear model.
Compute Loss (Step 6)
def compute_loss(self, X, y):
return (np.mean((y - self.predict(X)) ** 2) + self._get_regularization_loss()) ** 0.5It calculates the mean squared error between the predicted values and the actual target values y. Additionally, it incorporates the regularization loss if regularization is specified.
Regularization Loss Calculation (Step 7)
def _get_regularization_loss(self):
if self.reg == 'l1':
return self.reg_param * np.sum(np.abs(self.weights))
elif self.reg == 'l2':
return self.reg_param * np.sum(self.weights ** 2)
else:
return 0This private method computes the regularization loss based on the type of regularization (l1 or l2) and the regularization parameter. This loss is added to the main loss function to penalize large weights, thereby avoiding overfitting.
3.2: SGD in Sci-kit Learn and Tensorflow
Now, while the code above is very useful for educational purposes, data scientists definitely don’t use it on a daily basis. Indeed, we can directly call SGD with few lines of code from popular libraries such as scikit learn (machine learning) or tensorflow (deep learning).
SGD for linear regression in scikit-learn
from sklearn.linear_model import SGDRegressor # Create and fit the model model = SGDRegressor(max_iter=1000) model.fit(X, y) # Making predictions predictions = model.predict(X)
SGD regressor is directly called from sklearn library, and follows the same structure of other algorithms in the same library.
The parameter ‘max_iter’ is the number of epochs (rounds). By specifying max_iter to 1000 we will make the algorithm update the linear regression weights and bias 1000 times.
Neural Network with SGD optimization in Tensorflow
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import SGD
# Create a simple neural network model
model = Sequential([
Dense(64, activation='relu', input_shape=(X_train.shape[1],)),
Dense(1)
])
sgd = SGD(learning_rate=0.01)
# Compile the model with SGD optimizer
model.compile(optimizer=sgd, loss='categorical_crossentropy', metrics=['accuracy'])
# Train the model
model.fit(X, y, epochs=10)In this code we are defining a Neural Network with one Dense Layer and 64 nodes. However, besides the specifics of the neural network, here we are again calling SGD with just two lines of code:
from tensorflow.keras.optimizers import SGD sgd = SGD(learning_rate=0.01)
4: Advantages and Challenges
4.1: Why Choose SGD?
Efficiency with Large Datasets:
Scalability: One of the primary advantages of SGD is its efficiency in handling large-scale data. Since it updates parameters using only a single data point (or a small batch) at a time, it is much less memory-intensive than algorithms requiring the entire dataset for each update.
Speed: By frequently updating the model parameters, SGD can converge more quickly to a good solution, especially in cases where the dataset is enormous.
Flexibility and Adaptability:
Online Learning: SGD’s ability to update the model incrementally makes it well-suited for online learning, where the model needs to adapt continuously as new data arrives.
Handling Non-Static Datasets: For datasets that change over time, SGD’s incremental update approach can adjust to these changes more effectively than batch methods.
Overcoming Challenges of Local Minima:
The stochastic nature of SGD helps it to potentially escape local minima, a significant challenge in many optimization problems. The random fluctuations allow the algorithm to explore a broader range of the solution space.
General Applicability:
SGD can be applied to a wide range of problems and is not limited to specific types of models. This general applicability makes it a versatile tool in the machine learning toolbox.
Simplicity and Ease of Implementation:
Despite its effectiveness, SGD remains relatively simple to understand and implement. This ease of use is particularly appealing for those new to machine learning.
Improved Generalization:
By updating the model frequently with a high degree of variance, SGD can often lead to models that generalize better on unseen data. This is because the algorithm is less likely to overfit to the noise in the training data.
Compatibility with Advanced Techniques:
SGD is compatible with a variety of enhancements and extensions, such as momentum, learning rate scheduling, and adaptive learning rate methods like Adam, which further improve its performance and versatility.
4.2: Overcoming Challenges in SGD
While Stochastic Gradient Descent (SGD) is a powerful and versatile optimization algorithm, it comes with its own set of challenges. Understanding these hurdles and knowing how to overcome them can greatly enhance the performance and reliability of SGD in practical applications.
Choosing the Right Learning Rate
Selecting an appropriate learning rate is crucial for SGD. If it’s too high, the algorithm may diverge; if it’s too low, it might take too long to converge or get stuck in local minima.
Use a learning rate schedule or adaptive learning rate methods. Techniques like learning rate annealing, where the learning rate decreases over time, can help strike the right balance.
Dealing with Noisy Updates
The stochastic nature of SGD leads to noisy updates, which can cause the algorithm to be less stable and take longer to converge.
Implement mini-batch SGD, where the gradient is computed on a small subset of the data rather than a single data point. This approach can reduce the variance in the updates.
Risk of Local Minima and Saddle Points
In complex models, SGD can get stuck in local minima or saddle points, especially in high-dimensional spaces.
Use techniques like momentum or Nesterov accelerated gradients to help the algorithm navigate through flat regions and escape local minima.
Sensitivity to Feature Scaling
SGD is sensitive to the scale of the features, and having features on different scales can make the optimization process inefficient.
Normalize or standardize the input features so that they are on a similar scale. This practice can significantly improve the performance of SGD.
Hyperparameter Tuning
SGD requires careful tuning of hyperparameters, not just the learning rate but also parameters like momentum and the size of the mini-batch.
Utilize grid search, random search, or more advanced methods like Bayesian optimization to find the optimal set of hyperparameters.
Overfitting
Like any machine learning algorithm, there’s a risk of overfitting, where the model performs well on training data but poorly on unseen data.
Use regularization techniques such as L1 or L2 regularization, and validate the model using a hold-out set or cross-validation.
5: Beyond Basic SGD
5.1: Variants of SGD
Stochastic Gradient Descent (SGD) has several variants, each designed to address specific challenges or to improve upon the basic SGD algorithm in certain aspects. These variants enhance SGD’s efficiency, stability, and convergence rate. Here’s a look at some of the key variants:
Mini-Batch Gradient Descent
This is a blend of batch gradient descent and stochastic gradient descent. Instead of using the entire dataset (as in batch GD) or a single sample (as in SGD), it uses a mini-batch of samples.
It reduces the variance of the parameter updates, which can lead to more stable convergence. It can also take advantage of optimized matrix operations, which makes it more computationally efficient.
Momentum SGD
Momentum is an approach that helps accelerate SGD in the relevant direction and dampens oscillations. It does this by adding a fraction of the previous update vector to the current update.
It helps in faster convergence and reduces oscillations. It is particularly useful for navigating the ravines of the cost function, where the surface curves much more steeply in one dimension than in another.
Nesterov Accelerated Gradient (NAG)
A variant of momentum SGD, Nesterov momentum is a technique that makes a more informed update by calculating the gradient of the future approximate position of the parameters.
It can speed up convergence and improve the performance of the algorithm, particularly in the context of convex functions.
Adaptive Gradient (Adagrad)
Adagrad adapts the learning rate to each parameter, giving parameters that are updated more frequently a lower learning rate.
It’s particularly useful for dealing with sparse data and is well-suited for problems where data is scarce or features have very different frequencies.
RMSprop
RMSprop (Root Mean Square Propagation) modifies Adagrad to address its radically diminishing learning rates. It uses a moving average of squared gradients to normalize the gradient.
It works well in online and non-stationary settings and has been found to be an effective and practical optimization algorithm for neural networks.
Adam (Adaptive Moment Estimation)
Adam combines ideas from both Momentum and RMSprop. It computes adaptive learning rates for each parameter.
Adam is often considered as a default optimizer due to its effectiveness in a wide range of applications. It’s particularly good at solving problems with noisy or sparse gradients.
Each of these variants has its own strengths and is suited for specific types of problems. Their development reflects the ongoing effort in the machine learning community to refine and enhance optimization algorithms to achieve better and faster results. Understanding these variants and their appropriate applications is crucial for anyone looking to delve deeper into machine learning optimization techniques.
5.2: Future of SGD
As we delve into the future of Stochastic Gradient Descent (SGD), it’s clear that this algorithm continues to evolve, reflecting the dynamic and innovative nature of the field of machine learning. The ongoing research and development in SGD focus on enhancing its efficiency, accuracy, and applicability to a broader range of problems. Here are some key areas where we can expect to see significant advancements:
Automated Hyperparameter Tuning
There’s increasing interest in automating the process of selecting optimal hyperparameters, including the learning rate, batch size, and other SGD-specific parameters.
This automation could significantly reduce the time and expertise required to effectively deploy SGD, making it more accessible and efficient.
Integration with Advanced Models
As machine learning models become more complex, especially with the growth of deep learning, there’s a need to adapt and optimize SGD for these advanced architectures.
Enhanced versions of SGD that are tailored for complex models can lead to faster training times and improved model performance.
Adapting to Non-Convex Problems
Research is focusing on making SGD more effective for non-convex optimization problems, which are prevalent in real-world applications.
Improved strategies for dealing with non-convex landscapes could lead to more robust and reliable models in areas like natural language processing and computer vision.
Decentralized and Distributed SGD
With the increase in distributed computing and the need for privacy-preserving methods, there’s a push towards decentralized SGD algorithms that can operate over networks.
This approach can lead to more scalable and privacy-conscious machine learning solutions, particularly important for big data applications.
Quantum SGD
The advent of quantum computing presents an opportunity to explore quantum versions of SGD, leveraging quantum algorithms for optimization.
Quantum SGD has the potential to dramatically speed up the training process for certain types of models, though this is still largely in the research phase.
SGD in Reinforcement Learning and Beyond
Adapting and applying SGD in areas like reinforcement learning, where the optimization landscapes are different from traditional supervised learning tasks.
This could open new avenues in developing more efficient and powerful reinforcement learning algorithms.
Ethical and Responsible AI
There’s a growing awareness of the ethical implications of AI models, including those trained using SGD.
Research into SGD might also focus on ensuring that models are fair, transparent, and responsible, aligning with broader societal values.
Conclusion
As we wrap up our exploration of Stochastic Gradient Descent (SGD), it’s clear that this algorithm is much more than just a method for optimizing machine learning models. It stands as a testament to the ingenuity and continuous evolution in the field of artificial intelligence. From its basic form to its more advanced variants, SGD remains a critical tool in the machine learning toolkit, adaptable to a wide array of challenges and applications.
If you liked the article please leave a clap, and let me know in the comments what you think about it!