Is Mamba the End of ChatGPT As We Know It?

Two researchers have made the boldest claim in years: throwing the biggest algorithmic breakthrough of the 21st century out the window.
Named Mamba, it achieves what was once thought impossible: matching or beating the Transformer’s language modeling capabilities while being faster and a lot cheaper.
Everyone seems to be talking about it, so let’s uncover what Mamba is.
This insight and more I share in Medium have previously been shared in my weekly newsletter, TheTechOasis.
If you want to be up-to-date with the frenetic world of AI while also feeling inspired to take action or, at the very least, to be well-prepared for the future ahead of us, this is for you.
🏝Subscribe below🏝
Subscribe | TheTechOasis
The newsletter to stay ahead of the curve in AI
thetechoasis.beehiiv.com
The Gift that Keeps on Giving
Since its release in 2017, the Transformer architecture has become the ‘de facto’ choice for natural language modeling (models that generate text).
ChatGPT, Gemini, Claude, you name it, all are based on this seminal architecture.
The intrusiveness of this architecture is such that the ‘T’ in ChatGPT stands for ‘Transformer’.
A sequence-to-sequence model, (takes a sequence as input, be that a text passage or a sequence of pixels in an image, and gives you another sequence, usually new text) the secret sauce of the Transformer is the attention mechanism.
In straightforward terms, it performs a pair-wise multiplication among all tokens in the sequence, making them ‘talk’ to uncover the relationships between words.
Put simply, it indicates each word which words in the sequence it should be paying ‘attention’ to. For instance, the attention mechanism over a pronoun will allow it to pay attention to its noun.
Works wonderfully, but at a huge cost.
Mastering inefficiency
Put simply, the Transformer yields impressive performance at the cost of being extremely inefficient.
To understand how models like ChatGPT process language, imagine you’re halfway reading a Harry Potter book.
However, to successfully read the next page, you have to store all the pages read previously in your mind, the complete context. Put simply, to read the next word, you have to reread everything until that point again.
And so forth.
Transformers don’t actually re-read everything every time, they store a cache of previous calculations.
However, it forces them to store all those calculations in memory, which in comparison is as if you had to remember every single word you read earlier to successfully read the next one.
That’s how Transformers like ChatGPT process language. Seems very inefficient, right?
Yes, because it is.
But how do humans read a Harry Potter book?
Yeah, surely we do remember many things read until that point, but we forget irrelevant data like Hermione’s summer activities. They are not relevant to the storyline, so our mind forgets about it.
In other words, instead of retaining all the information read until now, we build a compressed representation of the story, keeping relevant data and erasing irrelevant points.
In layman’s terms, what I am trying to tell you is that Transformers don’t compress context. But as context isn’t compressed, the computation requirements of Transformers grow considerably as the text sequence grows larger.
Specifically, Transformers have quadratic and linear complexity for training and inference respectively.
In other words, in training, doubling the sequence quadruples the cost, and in inference (execution), doubles it.
So what do research labs do?
To avoid costs spiraling out of control, they limit the ‘workspace’ of the model to a context window, which is why ChatGPT and others have a limited size of text they can process.
Over the years, many different architectures with more ‘efficient’ attention mechanisms have been proposed, but the loss of performance has prevented them from really substituting the vanilla Transformer.
So what did Mamba’s researchers do?
Simply, throw attention, the biggest algorithmic breakthrough over the last years, out of the window.
Into a Stateful World
The Mamba architecture was born from a critical question: Can we model language as effectively as the Transformer while being far more efficient?
And the answer was yes, thanks to what we define as ‘state’.
Circling back to the Harry Potter example, when we are reading a book, we keep an updated state of the book; we slowly build a compressed, approximated understanding of what’s going on, keeping the key elements stored and rejecting the rest.
In essence, this is exactly what Mamba does.
Give me 3 ‘s’
Just like the attention module sits at the core of the Transformer, the Selective State Space Model (Selective SSM) sits at the core of Mamba.
An SSM is a rather new language modeling architecture inspired by state space models from the 1960s.
In simple terms, the model keeps a ‘state’, or memory, that serves as context. In other words, the next output will be a function of the current input and my current state up till that point.
If the current input is ‘Harry’, the SSM will use its state to infer that the next word is probably ‘Potter’. As it has probably seen both words together earlier, the state will remember this.
However, ChatGPT can predict ‘Potter’ too, right?
Yes, but the key thing here is that Selective SSMs keep only the context that matters in memory, which means they achieve linear and constant complexities for training and inference.
In other words, if the sequence doubles the cost of training doubles (Transformers quadruple) while the inference cost remains constant no matter the length!
Constant inference complexity is achieved because the state has a fixed size, the cost doesn’t increase no matter how long the sequence is, the model simply stores the key information and forgets the rest.
On the flipside, these models’ predictions are as good as their compressed context is.
But how can Selective SSMs choose what context to keep and Transformers don’t?
The answer to that is selectivity.
To choose or not choose, the question is
What makes Mamba unique is that its SSM module is selective, it chooses what context to keep and what to discard. In other words, it performs what we define as compression by selection.
Like any other state space model, the model is driven by two equations: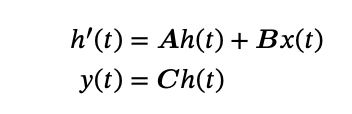 With parameters A, B, we first obtain the state h (the memory) and then the new output, y, with C.
With parameters A, B, we first obtain the state h (the memory) and then the new output, y, with C.
You can think of these parameters as ‘gates’.
- As A multiples the previous state, it decides if it’s relevant or not for the next prediction.
- B decides if the current input is important or not, computing the new state.
- Ultimately, C decides how this information is turned into an output.
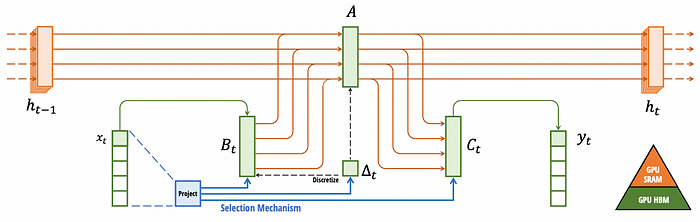
The key to allowing this is that, unlike all previous architectures, Mamba is input and time-dependent.
In this case, researchers decided to make A constant, although it can be parametrized too.
 Selective SSMs
Selective SSMs
As we want the model to be able to compress context, it has to be capable of selecting what should be used as context and what not.
For instance, if the next word is ‘um’, so typical of our dear Brits, that is probably not very relevant to context, and, thus, gets rejected.
To allow this phenomenon, as mentioned, Mamba introduces a new paradigm where the weights of the model depend on the input and change over time.
In the Transformer, the weights are fixed, meaning that it can’t choose what to keep or not. By making the weights a variable of the input, they can adapt to every input.
And what does the parameter ∆ do?
Serves as the main selective gate, ultimatemly deciding how much importance the model is going to give to the input x.
Model-wise, this SSM module is inserted into a Mamba block, and stacked homogeneously to build the actual model.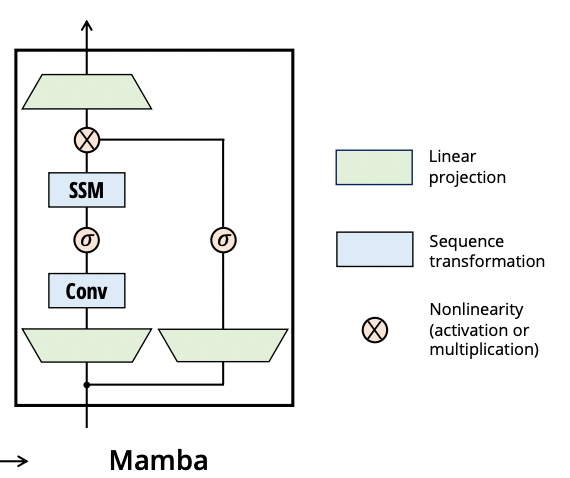 Mamba block
Mamba block
But if the key was simply to make the weights input-dependent, why wasn’t this done in earlier State Space Models?
State Space Models are recurrent models, meaning that input is treated sequentially. Or, to put it another way, their computations aren’t parallelizable… unless you make the model Linear-time invariant, or LTI.
As LTI State Space Models are linear and don’t change over time, we can apply convolution to the two equations we saw earlier without having to materialize the hidden state, reducing costs drastically and parallelizing the computation.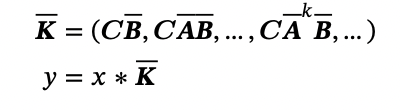 With convolution, we don’t need to calculate h to calculate y
With convolution, we don’t need to calculate h to calculate y
However, as Mamba makes the weights of the model input-dependent, you lose the convolution capability that unlocks parallelization, fundamental to running these models on GPUs.
To solve this, researchers made Mamba hardware-aware, meaning it only materializes the hidden state, something you must do as the model can’t apply convolutions, into memory at the super-fast SRAM level.
What they actually do is perform kernel fusion, a parallel scan instead of a convolution, and a recomputation of the intermediate states during backpropagation in training.
Without going into much detail, what they are essentially doing is applying several optimizations to reduce the number of I/O memory events, which in turn means that, although the model is recurrent, is still as efficient as Transformers.
But the real question is: how does Mamba fare in comparison to Transformers?
Exciting, but Questions Remain
Tested at different small sizes (up to 7 billion parameters), Mamba beats every other model, including GPTs of similar sizes, both in perplexity (a measure of how well a model predicts the next token) and accuracy.
It even manages to match the results of a Transformer more than two times its size!
Also, it shows no accuracy decrease with increased length, something unheard of until now: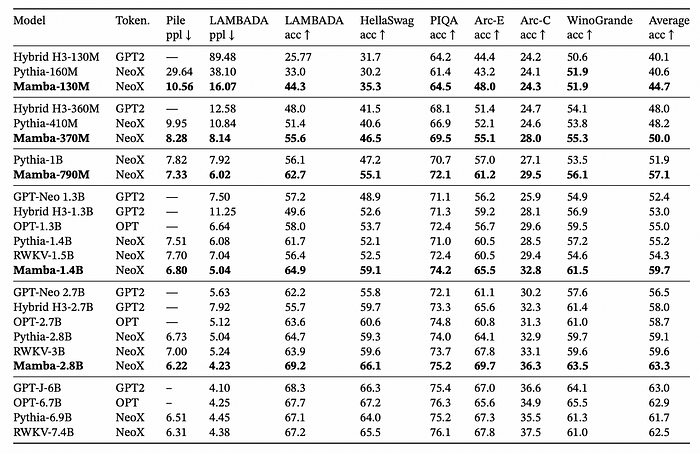 However, Mamba has yet to be proven at big sizes.
However, Mamba has yet to be proven at big sizes.
Either way, it proves that recurrent networks to model language are making a stellar return, as Mamba’s results are not only a statement of quality, but the fact that they successfully incorporate state into a scalable solution makes the architecture in itself a thing of beauty and, more importantly, it simply makes sense.
Were these results to extrapolate to LLM state-of-the-art sizes, we can confidently say this is the end of ChatGPT as we know it, and we could soon see the birth of ChatGPM, with ‘M’ for Mamba.



































