Portfolio Theory: The Cornerstone of Financial Strategies

Portfolio theory plays a pivotal role in financial management. This article will explore the fundamental principles of this theory, developed by Markowitz, and its impact on financial strategies.This theorem attempts to theoretically prove that in a distributed system, Consistency, Availability, and Partition Tolerance cannot be achieved simultaneously. It is often illustrated with the following diagram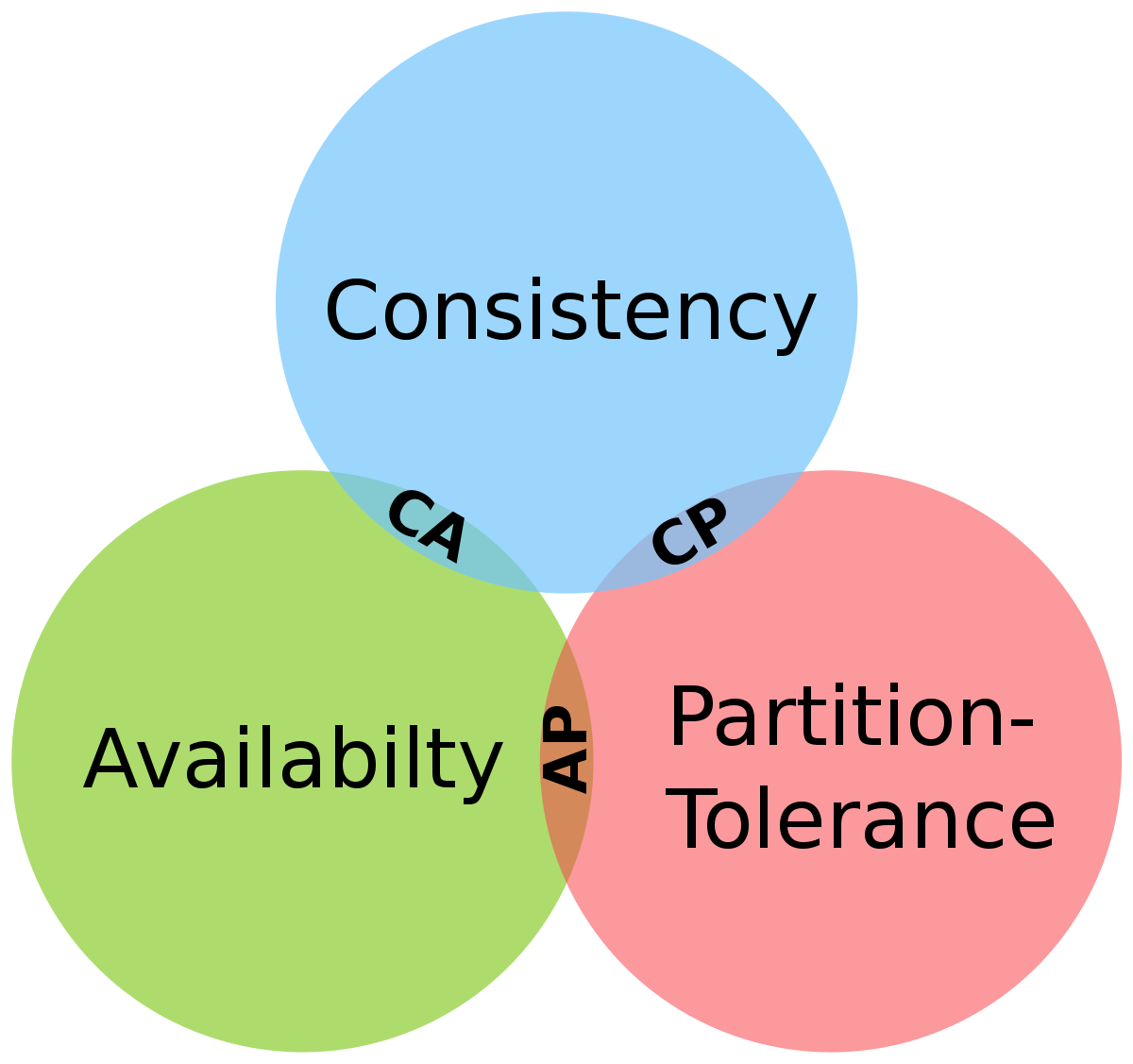 What is Portfolio Theory?
What is Portfolio Theory?
Markowitz's portfolio theory aims to find a balance between risk and return. It focuses on investors diversifying their portfolios to maximize returns while minimizing risk.
The Significance of Portfolio Diversification:
The article emphasizes why portfolio diversification is critical according to portfolio theory. A diversified portfolio spread across different asset classes and industries effectively distributes risk.
Balance of Risk and Return:
Explaining how portfolio theory provides investors with a balance between risk and return, the article delves into how it guides effective decision-making in financial strategies.
Applications of Portfolio Theory:
Portfolio theory is widely used in corporate finance, asset management, and individual investment strategies. Practical examples illustrate its impact on daily financial decision-making.
Criticisms and Emerging Approaches:
The article addresses criticisms directed at portfolio theory and explores evolving financial approaches, evaluating the limitations and evolution of this theory.
In this text, we will frequently utilize the terms 'Cluster' and 'Node.' Therefore, let's begin by thoroughly understanding what these concepts mean in distributed architectures
What is Node?
In a distributed architecture, a "node" is a term given to a single machine or server that is physically independent but communicates with other nodes over a network.
What is Cluster?
A cluster is typically formed by nodes that have similar hardware and software, coming together for a common purpose. This structure provides higher availability, reliability, and scalability than what can be achieved with a single server.
Cluster Architecture from an External Perspective
Determining whether a system has a cluster architecture from an external standpoint is often challenging. However, many popular applications or systems today include multiple clusters, each containing hundreds of nodes. For example, Instagram has multiple Cassandra Clusters, and within these clusters, there are over 1000 Cassandra Nodes in total.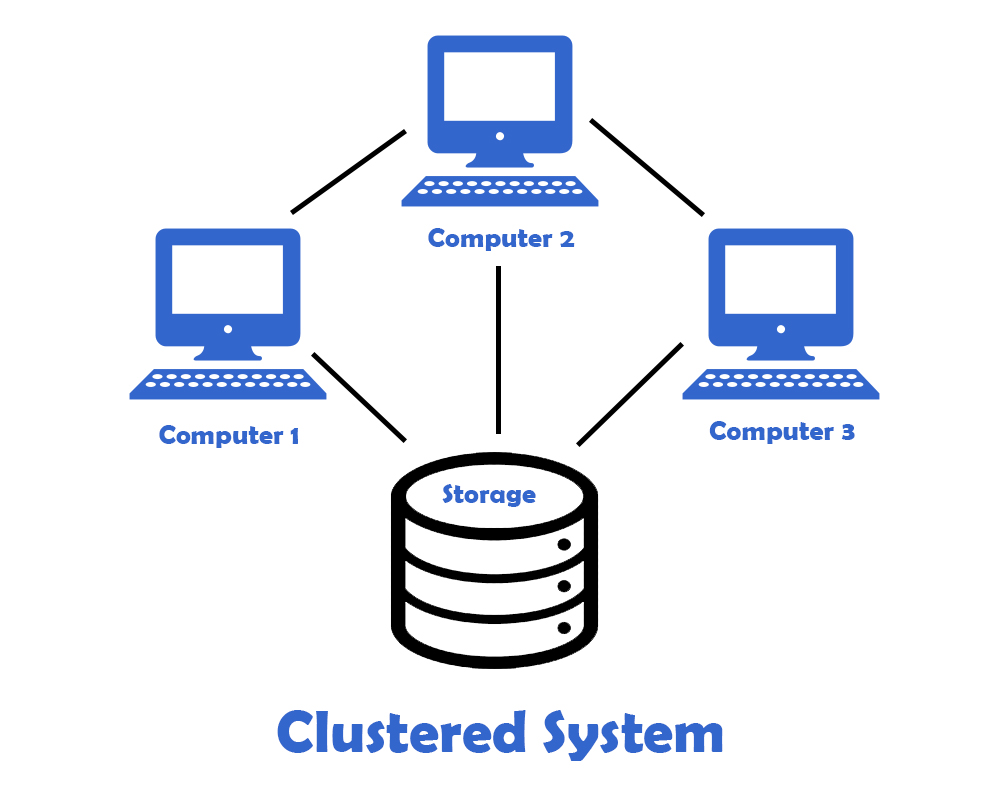
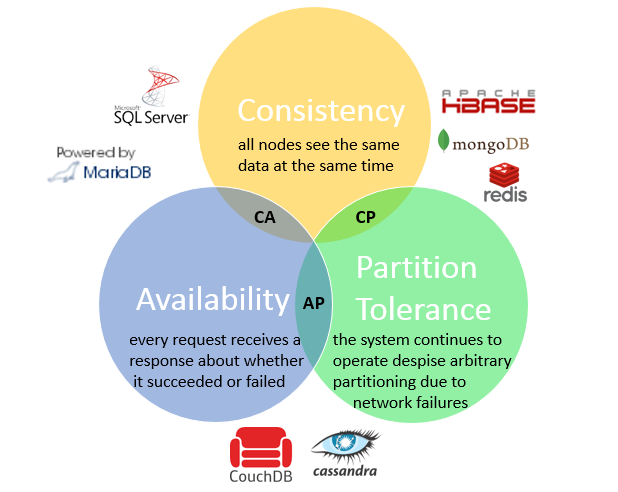
Consistency
Any read request sent to the system should be able to retrieve the most recent value that has been updated for the relevant record under all circumstances. If it cannot be retrieved, an error should be given, and data whose freshness is doubted should never be shared with requesting parties.
Availability
The ability of a distributed system to respond to any requests at any given time implies that the system has high availability. Even if a node in any cluster becomes inoperable, the system should be able to continue its operation with other nodes.
Partition Tolerance
Here, the term "partition" actually refers to network partitioning, meaning that the components of your system are in different networks.Partition Tolerance is the ability of the system to continue its operation in the event of any communication failure between nodes.
While a node may experience communication issues with other nodes, it can still be directly accessible by a client. This implies that other nodes may not be aware of any operations that could be performed on that particular node, or, in conditions where awareness is mandatory, it may not be accessible.As mentioned earlier, if Partition Tolerance exists, either Availability or Consistency should be chosen.
In distributed systems, it is common for data centers to be located in different places, often on different machines and networks. Therefore, Partition Tolerance is generally indispensable for distributed architectures. The rise of NoSQL databases is partly due to their ability to easily overcome the Single Point of Failure issue. Having a single network infrastructure for a data center also creates a kind of single point of failure.
In relational databases (RDBMS), the relationship between data and the prevention of data easily spreading to different nodes was a challenge. Thus, NoSQL databases do not include foreign keys, joins, or relationships between data. The lack of relationships makes data much easier to distribute across different nodes in the system, enabling NoSQL databases to be easily scalable.
In conclusion, in a distributed system, the luxury of not providing Partition Tolerance is generally not available. When you look at database systems like MongoDB, Cassandra, etc., you can see that none of them compromises on Partition Tolerance and that they make a choice between Availability and Consistency.
Therefore, why does the CAP theorem claim that these three properties cannot exist simultaneously? Let's take a look at them:
CP Advocates
Availability is sacrificed.
Based on Consistency and Partition Tolerance.
In case of a partition between two nodes, the inconsistent node is shut down.
AP Advocates
Consistency is sacrificed.
Relies on Availability and Partition Tolerance.
In the event of a partition between two nodes, both will be accessible for availability. However, consistency between the two nodes is not guaranteed. In this case, there is no consistency between the two nodes.
CA Advocates
Partition Tolerance is sacrificed.
Based on Availability and Consistency.
All nodes are accessible, and each node is consistent with the others. There is no partition between nodes.
(CA) Why can't it be (P)?
Let's say you wrote the data to server 1, and servers 2 and 3 lost network connectivity with server 1. The updated version of the data did not reflect on servers 2 and 3. The system cannot tolerate partitioning when it is CA.
(AP) Why can't it be (C)?
Consider having two servers (servers) where the value X exists on both servers. The network between the servers collapses. You update the X value on one of the servers. When querying, the data on the two servers will be different. It cannot be C.
For data streams like the number of likes on Twitter or Facebook, eventual consistency, where the data is updated between nodes, is acceptable. Systems like Cassandra and Dynamo follow this approach.
(CP) Why can't it be (A)?
If your goal is both consistency and the ability to store data in partitions, when the connection between the three servers is lost, the write feature of A (Availability) will disappear. If you write, you compromise consistency. Therefore, you can only perform reads in this situation.
Systems like MongoDB databases are CP-compliant. They default to being strongly consistent.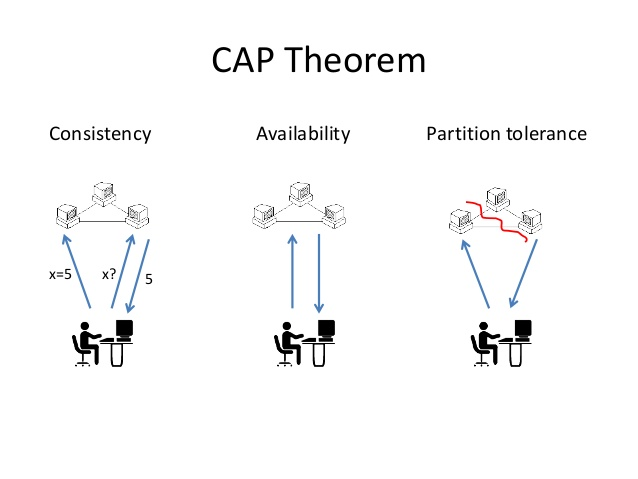















![[ℕ𝕖𝕧𝕖𝕣] 𝕊𝕖𝕝𝕝 𝕐𝕠𝕦𝕣 𝔹𝕚𝕥𝕔𝕠𝕚𝕟 - And Now What.... Pray To The God Of Hopium?](https://cdn.bulbapp.io/frontend/images/79e7827b-c644-4853-b048-a9601a8a8da7/1)















![[LIVE] Engage2Earn: McEwen boost for Rob Mitchell](https://cdn.bulbapp.io/frontend/images/c798d46f-d3b8-4a66-bf48-7e1ef50b4338/1)
