What is reinforcement learning? How does reinforcement learning work?

DRL Experiment
This details the development of a deep reinforcement learning (DRL) trading bot designed to trade cryptocurrency. The author, Nicola Di Santo, explains the project's background, drawing inspiration from a previous research paper that attempted to apply DRL techniques to cryptocurrency trading. 
Reinforcement learning (RL) is a machine learning technique where an agent learns to make decisions in an environment by interacting with it and receiving feedback in the form of rewards or penalties. [1] The goal of the agent is to develop a policy that helps it maximize its cumulative reward over time. This aligns with our previous discussion where we highlighted that an agent learns to make decisions by interacting with its environment. It receives rewards or penalties for its actions, aiming to learn a policy that maximizes cumulative reward.
The core concept involves training an agent to make trading decisions (buy, sell, hold) based on market data. The agent learns through interactions with an environment that simulates the cryptocurrency market, aiming to maximize profit. The environment provides the agent with the current market state and rewards it based on its trading actions.
The project uses a replay memory buffer in Deep Reinforcement Learning to enable the agent to randomly sample past experiences.
Where To Find It
You can find the project on GitHub: Project Repo.
The repo also contains a report I used to describe the bot to the professor at the time, with some pills of background math theory.
Background
In the paper we based the implementation on the authors try to adapt some Deep Reinforcement Learning techniques, namely DQN, Double DQN, and Dueling Double DQN, to allow an agent to trade cryptocurrency stocks. The trading environment simulation gives the possibility to either buy, hold or sell a position. The profit made during trading is measured with the Sharpe ratio index or a simple profit difference function.

How it works?
The whole deep reinforcement learning world is based on a simple fact: neural networks are universal function approximators, we can simply create a NN model and train it to resemble the Q functions or whatever RL functions you plan to use.
The Environment
We can think of the Environment as a wrapper around our data with minimal access methods and a bit of logic. In detail, you can only access data by calling the method get_state it gives to you the current stock price window, corresponding to the environment state. Then you can interact with it only with the step method. It simply acts as the Agent on the environment (the input parameter), computes the reward for the agent and it updates some data structures to keep track of some econometric indexes during time, used to evaluate the model. In detail, an Agent can either buy, sell, hold/do-nothing. If the agent has bought at a given price and then in the next step it does nothing this means he is holding a position because he thinks the price is going to rise. If the Agent has no position and he does not buy then he is doing nothing because he thinks it is not convenient to buy now.
The Agent
Reinforcement learning is a type of machine learning where an agent learns to make decisions by interacting with its environment. The agent receives rewards or penalties for its actions, and its goal is to learn a policy that maximises its cumulative reward over time.
The Agent is a wrapper for the model and it takes care of the training and inference logic. The test phase test in the agent assumes you have an already trained model and you have exported it. It then loads the exported model into one of the models defined into models according to the parameters and then starts the canonical observe-act-collect loop, saving all the metrics needed to evaluate the model. The training phase trainis a bit more complex apparently because it included model optimization. The loop becomes observe-act-collect-optimize and the optimize phase requires a bit of background knowledge to be mastered (perfectly covered on the pytorch doc, the code here is only an adaptation to a different kind of use case). The code in the repo comes with some pretrained models
- profit_reward_double_ddqn_model,
- profit_reward_double_dqn_model,
- profit_reward_dqn_model,
- sr_reward_double_ddqn_model,
- sr_reward_double_dqn_model,
- sr_reward_dqn_model
and the main.py only evalutes those pre-trained models. If you want also to train them you should check the train_test.py script.
Replay Memory Buffer
The replay memory buffer is a useful tool that is perfectly explained in this article from Jordi Torres that I get like to quote:
We are trying to approximate a complex, nonlinear function, Q(s, a), with a Neural Network. To do this, we must calculate targets using the Bellman equation and then consider that we have a supervised learning problem at hand. However, one of the fundamental requirements for SGD optimization is that the training data is independent and identically distributed and when the Agent interacts with the Environment, the sequence of experience tuples can be highly correlated. The naive Q-learning algorithm that learns from each of these experiences tuples in sequential order runs the risk of getting swayed by the effects of this correlation. We can prevent action values from oscillating or diverging catastrophically using a large buffer of our past experience and sample training data from it, instead of using our latest experience. This technique is called replay buffer or experience buffer. The replay buffer contains a collection of experience tuples (S, A, R, S′). The tuples are gradually added to the buffer as we are interacting with the Environment. The simplest implementation is a buffer of fixed size, with new data added to the end of the buffer so that it pushes the oldest experience out of it. The act of sampling a small batch of tuples from the replay buffer in order to learn is known as experience replay.
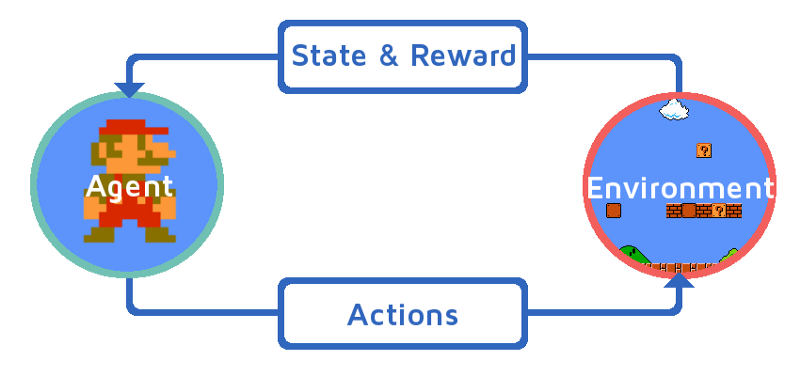
About state & reward:
- State is the agent's current observation about the environment, which provides context for making decisions. For example, in a trading environment, this may be the current price of a stock.
- Reward - this is the signal that the agent receives after performing the\action. It evaluates the quality of an agent's actions and can be positive for profitable decisions or negative for losses.
About actions:
- The agent selects * * action** based on the current state of. In the context of trading, this may be a decision to buy, sell, or hold a stock.
- Performing an action causes the environment to switch to a new state.
Coding
Here is an example of how to i build service and share to GitHub

Conclusion
Although DRL technologies are commonly used in video games using artificial intelligence, their potential is not limited to this area of development. These methods of artificial intelligence represent a promising direction that can be applied in various fields of science.
While this may sound interesting, I would advise you to maintain a certain amount of skepticism when reading such materials.
After analyzing the report on this project and the original article that it is based on, you will notice that they do not contain error graphs or similar indicators. This may indicate that the information provided does not reflect the full picture of the situation. 
If you are a quantum, me invite you to take part in the CrunchDAO competition. This is a unique opportunity to demonstrate your skills and win valuable prizes. Registration is open, don't miss the chance to prove yourself! Send your solutions and fight for victory. CrunchDAO is a place where the best minds of the world meet. Join us and show us what you can do!