Computer Vision (Part 2)-Computer Vision Tasks and Applications

📚Chapter: 1-Introduction :Computer Vision Tasks and Applications
Table of Content
- 1- Content Recognition
- 2. Video Analysis
- 3. Content-aware Image Editing
- 4. Scene Reconstruction
we will explore the main computer vision tasks and the most popular application for each task.
1- Content Recognition
1.1. Image Classification
Image classification is one of the main tasks in the field of computer vision [1].In this task, the trained model assigns a certain class to the image based on a predefined set of classes. The figure below is the famous CIFAR-10 dataset [1], which consists of 80 million images of ten classes. In the image classification task, the model is trained to assign the input image to one of the predefined ten classes, as shown in the figure below. The computer analyzes an image in the form of pixels. It does it by considering the image as an array of matrices with the size of the matrix reliant on the image resolution. Put simply, image classification, in a computer’s view, is the analysis of this statistical data using algorithms. In digital image processing, image classification is done by automatically grouping pixels into specified categories, so-called classes. The algorithms segregate the image into a series of its most prominent features, lowering the workload on the final classifier. These characteristics give the classifier an idea of what the image represents and what class it might be considered into. The characteristic extraction process makes up the most important step in categorizing an image, as the rest of the steps depend on it.
The computer analyzes an image in the form of pixels. It does it by considering the image as an array of matrices with the size of the matrix reliant on the image resolution. Put simply, image classification, in a computer’s view, is the analysis of this statistical data using algorithms. In digital image processing, image classification is done by automatically grouping pixels into specified categories, so-called classes. The algorithms segregate the image into a series of its most prominent features, lowering the workload on the final classifier. These characteristics give the classifier an idea of what the image represents and what class it might be considered into. The characteristic extraction process makes up the most important step in categorizing an image, as the rest of the steps depend on it.
Image classification applications:
There are a lot of real-world applications for image classification [1].
- Automated inspection and quality control: Image classification can be used to automatically inspect products on an assembly line and identify those that do not meet quality standards.

- Classification of skin cancer: Another application of image classification in the healthcare domain is automating the classifying of skin images into malignant and begin [1].
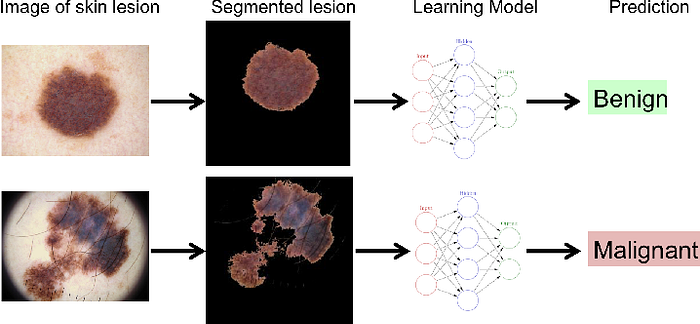
- Land use mapping: Image classification can be used to automatically map land use and identify different land types.
- Security and Medical Imaging: Finally, two more surveillance is a huge issue. This ideas of being able to monitor environment for crowd safety, a variety of reasons.

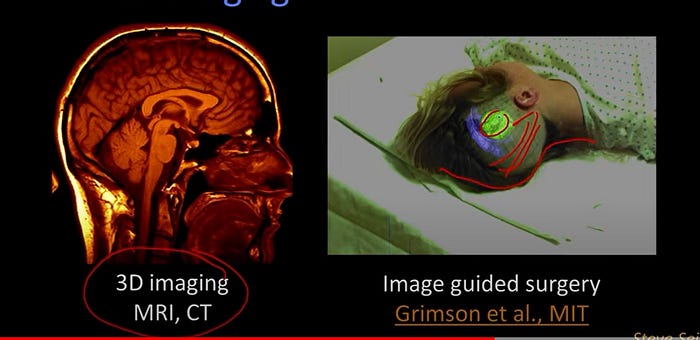
- These are screenshots taken from Siemens sells a system for doing port monitoring.Just to know whether, say, people are loitering, or vehicles are approaching that aren’t supposed to be. This is also a computer vision. A more direct effect on a single individual with computer vision is work in medical imagining. Okay, so here you see an example. There’s all sorts of 3D imaging, MRI, CAT scan, stuff like that, but here you see some work.This came out of Eric Grimson’s lab a while ago at MIT where on a screen, a the computer vision system is registering the skull that’s on the table with a model that has been created from the 3D imaging. So while, when the surgeon looks at this monitor, he sees the real person, and by the way, if there were a scalpel here, he’d see the hand with the scalpel or drill or whatever you’re using to make a hole in the person’s head. And where the various structures are underneath that you wanted to see, and that’s also computer vision.
1.2. Object Identification
As mentioned, image classification works by assigning classes or labels to the picture from a predefined set of labels, object identification recognizes specific instances of the class. For example the image classification tasks, the focus is to classify the face’s pictures, in object identification, the focus is on identifying the person and recognizing them. Therefore, object detection can be seen as a clustering algorithm to cluster similar instances with each other [1].
1.3. Object Detection and Localization
Sometimes we also need to extract the location of an object that is present in the image. This is when we can use Object Detection, another well-known and useful Computer Vision task [2] Here instead of just the label, the system also provides you with bounding box coordinates to tell where exactly the object is located in the image.
Here instead of just the label, the system also provides you with bounding box coordinates to tell where exactly the object is located in the image. Another important task of content recognition is object detection. Object detection is the task of detecting instances of objects of a certain class within an image. Object detection is often a preliminary task before further computations, such as in facial recognition, in which you have to detect the faces first and crop it before recognition [1].
Another important task of content recognition is object detection. Object detection is the task of detecting instances of objects of a certain class within an image. Object detection is often a preliminary task before further computations, such as in facial recognition, in which you have to detect the faces first and crop it before recognition [1].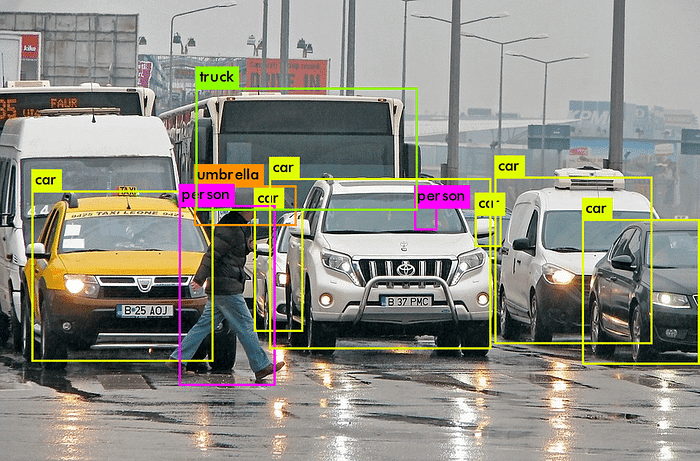 There are many industrial use cases of classification systems and their variations. A popular application is Facial Recognition. Where a computer program can recognize and identify the people in images by analyzing their faces. Facial Recognition is used almost everywhere from employee attendance to unlocking mobile phones.[2]
There are many industrial use cases of classification systems and their variations. A popular application is Facial Recognition. Where a computer program can recognize and identify the people in images by analyzing their faces. Facial Recognition is used almost everywhere from employee attendance to unlocking mobile phones.[2] It’s even used by Facebook to tag people, It identifies people in uploaded images/videos and automatically suggests to tag them if they’re in your mutual friends, etc [2].
It’s even used by Facebook to tag people, It identifies people in uploaded images/videos and automatically suggests to tag them if they’re in your mutual friends, etc [2]. Another thing that’s very common these days is face detection. Just about any digital camera that you buy today, you pick it up, using the default setting, it will find the faces. So, here’s an example. One of the cool things, by the way, is bunch of lectures in the future, we’ll talk about the technology that basically does exactly this. So the next time, so when we get to those, you pick up a camera and it finds the faces. You’ll say, oh, I know how they’re doing that. But actually now, cameras can do more. I think the one on the left, I think is from the web, from Fiji, that if you take a picture of somebody, and they blink. You know, and that can be really annoying, it’ll tell you they blinked. Maybe even more interestingly, Sony has something called the Smile Shutter, which will watch for people. And you sort of press it, and say, take a picture now. But actually it waits until you, it sees the person smile. And even further these days, there are cameras that will recognize who you are. So this is a screen taken from a shot where it does camera based login. So it knows about a bunch of different people. You walk up to the computer, you say, yo, computer it’s me. Actually you don’t have to say anything, and the computer says, it’s you. And it logs you in. So that’s face recognition. We’re going to talk also, a little bit, about face recognition. Although the face detection stuff techno, that technology is one that will be sort of more fundamental to the class [2].
Another thing that’s very common these days is face detection. Just about any digital camera that you buy today, you pick it up, using the default setting, it will find the faces. So, here’s an example. One of the cool things, by the way, is bunch of lectures in the future, we’ll talk about the technology that basically does exactly this. So the next time, so when we get to those, you pick up a camera and it finds the faces. You’ll say, oh, I know how they’re doing that. But actually now, cameras can do more. I think the one on the left, I think is from the web, from Fiji, that if you take a picture of somebody, and they blink. You know, and that can be really annoying, it’ll tell you they blinked. Maybe even more interestingly, Sony has something called the Smile Shutter, which will watch for people. And you sort of press it, and say, take a picture now. But actually it waits until you, it sees the person smile. And even further these days, there are cameras that will recognize who you are. So this is a screen taken from a shot where it does camera based login. So it knows about a bunch of different people. You walk up to the computer, you say, yo, computer it’s me. Actually you don’t have to say anything, and the computer says, it’s you. And it logs you in. So that’s face recognition. We’re going to talk also, a little bit, about face recognition. Although the face detection stuff techno, that technology is one that will be sort of more fundamental to the class [2].
Object detection application:
Object detection is one of the most used computer vision applications in real life. It has been applied in most of the domains, such as [1]:
- Danger detection in security and surveillance: A wide range of security applications in video surveillance are based on object detection, for example, to detect people in restricted or dangerous areas, suicide prevention, or automating inspection tasks in remote locations with computer vision.
- Vehicle detection with AI in Transportation and logistics domain: Object detection is used to detect and count vehicles for traffic analysis or to detect cars that stop in dangerous areas, for example, on crossroads or highways.

- Medical feature detection in the Healthcare domain: Object detection has helped in many breakthroughs in the healthcare domain. Because medical diagnostics rely heavily on the study of images, scans, and photographs, object detection involving CT and MRI scans has become extremely useful for diagnosing diseases, for example, with ML algorithms for tumor detection.
- Self-driving Cars rely on Object Detection techniques to determine the location of objects like people, traffic signs, etc. This information tells the car to stop if an object is approaching it or too close to it.[2]

- here is this company, Evolution Robotics, that had developed this thing called Lane Hawk, which basically prevented some of you. None of you. From putting stuff on the bottom of a basket and then wheeling it out and forgetting to mention to the cashier that it was there. This is actually a huge problem. And the system, you can see the camera here [2].

- Right, see, that’s a camera down here, looking at this. I wonder if we’re going to have to, like, erase that that’s a beer. Yeah, you see, now nobody can see. Okay, you can’t tell what that is. Okay. And it can detect what that is, which is not only pretty cool. But if you go on their website they’ll tell you that five years later, that product was bought by a different company. So, there’s money to be made in computer vision. Go do a really cool startup. Object recognition used to require a lot of computing power [2].

- It’s, the computing power has gotten smaller. And it allows us to now operate in smaller packages. So, there’s this whole area of augmented reality and object recognition by mobile devices.So, here’s a system of where you, you’re showing it a picture of this statue.It recognizes who this is and what the monument is. And here’s an old picture from Nokia, where you can actually go off to the web, pull out information and display it to you. So for a while we were talking about doing this on smart phones, now it sits on your face. This is Professor Thad Starner, a Georgia Tech professor as well. He was instrumental in the developement of Google Glass. And one of the things that Glass does is you’ve got a camera looking out of what you’re seeing. And can, through the same object recognition methods, can give you information about what you’re looking at. And this is also part of computer vision [2].

- Smart Cars:
Another area that you know, really blossomed lately is the use of computer vision for automotive.This is a, a website, web picture taken from Mobileye, which is a company out of Israel. And they’ve developed all sorts of technologies that use computer vision that are relevant to automobiles. Everything from automatically recognizing signs to, here it’s a little hard to see, red outline. The system is automatically identifying where the pedestrians are. They have a system that alerts you if pedestrians getting close and you’re, seem to be going too fast. You can also build systems that either brake or slow down or whatever. But the idea is that computer vision has really gotten into smart cars.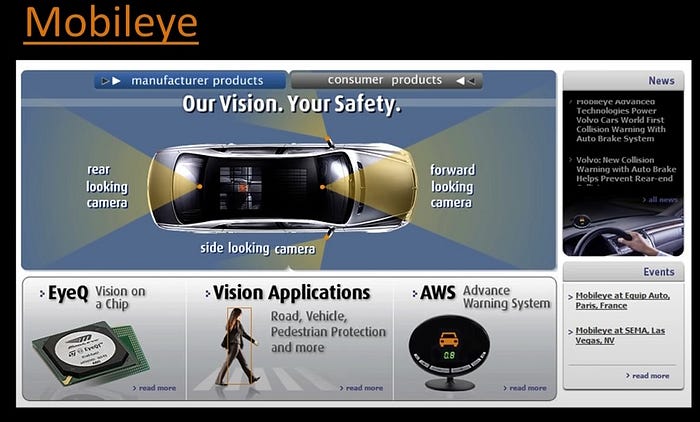 And in fact, smart cars are here. So this car, some of you know, that is Stanley. Stanley was the Stanford. That’s the little red S there. Entry into the Urban Grand Challenge run by DARPA. And it was started by. Stanley was run by this guy. What’s his name? Oh yeah, Thrun something, I don’t know Sebastian. He’s the guy who also started Udacity. He’s sort of a way under achieving, no ambition kind of guy. They won that. And then Sebastian, because he’s just out there,
And in fact, smart cars are here. So this car, some of you know, that is Stanley. Stanley was the Stanford. That’s the little red S there. Entry into the Urban Grand Challenge run by DARPA. And it was started by. Stanley was run by this guy. What’s his name? Oh yeah, Thrun something, I don’t know Sebastian. He’s the guy who also started Udacity. He’s sort of a way under achieving, no ambition kind of guy. They won that. And then Sebastian, because he’s just out there, convinced Google to get involved in the making the automobile process. The self driving car, which most of you have heard about. Here’s a picture of it out on the highway. And the real mark that these things are here today is. States now have starting passing legislation that helps detail, well who’s at fault if an accident happens on a particular road and it’s a self driving car. So this is where technology starts to hit policy and economics, and that’s when you know it’s real
convinced Google to get involved in the making the automobile process. The self driving car, which most of you have heard about. Here’s a picture of it out on the highway. And the real mark that these things are here today is. States now have starting passing legislation that helps detail, well who’s at fault if an accident happens on a particular road and it’s a self driving car. So this is where technology starts to hit policy and economics, and that’s when you know it’s real
1.4. Object and Instance Segmentation
Image segmentation is a method of dividing a digital image into subgroups called image segments, reducing the complexity of the image and enabling further processing or analysis of each image segment. Technically, segmentation is the assignment of labels to pixels to identify objects, people, or other important elements in the image. In the figure below, the image was segmented such that each instance will be given a certain color, as shown [1]:
Object and instance segmentation applications
Image segmentation is a key building block of computer vision technologies and algorithms. It is used for many practical applications, including medical image analysis, computer vision for autonomous vehicles, face recognition and detection, video surveillance, and satellite image analysis [1].
1.5. Pose Estimation
Pose Estimation can have different meanings depending on the targeted tasks. For rigid objects, it usually means the estimation of the objects’ positions and orientations relative to the camera in the 3D space. This is especially useful for robots so that they can interact with their environment (object picking, Collision avoidance, and so on). It is also often used in augmented reality to overlay 3D information on top of objects [1] For non-rigid elements, pose estimation can also mean the estimation of the positions of their sub-parts relative to each other. More concretely, when considering humans as non-rigid targets, typical applications are the recognition of human poses (standing, sitting, running, and so on) or understanding of sign language [1].
For non-rigid elements, pose estimation can also mean the estimation of the positions of their sub-parts relative to each other. More concretely, when considering humans as non-rigid targets, typical applications are the recognition of human poses (standing, sitting, running, and so on) or understanding of sign language [1].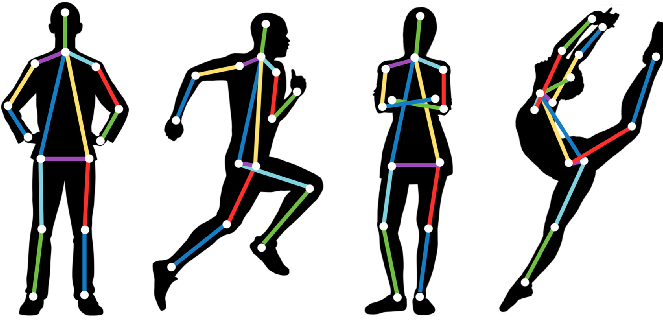 .
.
1.5- OCR (Optical Character Recognition)
The interesting question is sort of what is the state of the art in computer vision now? What are things that are people doing with computer vision? How might that compare a little bit to the way humans do vision? Here is a, a simple example of stuff that, in fact used to be sort of considered to be difficult, but is actually now pretty standard. So let’s talk about simple optical character recognition. So here’s an example from some license plate readers. And license plates are somewhat easier because there’s a fixed font. In fact, not that long ago doing OCR was considered very hard. Today if you have a scanner, or if you have Adobe Acrobat, it comes with OCR built in. Because that’s how ubiquitous and sort of easy it is. A little more challenging, many of you may have started using automated teller machines. Where you can deposit bank checks with hand written numbers that are the amount. And also, for quite a while the Post Office has been recognizing the ZIP codes using, machines. Again, on handwritten envelopes. So that’s an example of computer vision extracting the meaning. What are the numbers that are there? [2].

2. Video Analysis
Computer vision algorithms are applied not only to single images but also to videos. Some tasks require taking into consideration image sequences of the videos as a whole in order to take temporal and spatial consistency into account. We will explore the most famous tasks and applications of computer vision for videos [1].
2.1. Object Tracking
Object tracking is the process via which computers are able to detect, understand, and keep an eye on objects across a stream of images or videos. It is one of the most widespread applications of artificial intelligence (AI) and machine learning (ML), enabling your visual data processing needs to be automated and streamlined to maximal levels. The underlying deep learning algorithms take inspiration from our biological nervous system to form a layered yet intricate network of data transmission and learning capacities [1].
Object tracking solutions enable us to perform meaningful actions on visual data obtained via different types of cameras. Using suitable object detection algorithms coupled with tracking models, you can train a machine to not just recognize one or more unique objects or persons in a particular image but also identify them in subsequent frames and follow their trajectory in a video stream [1].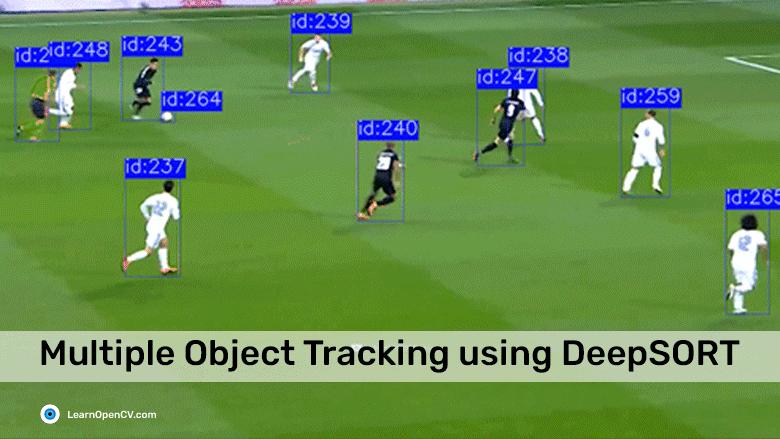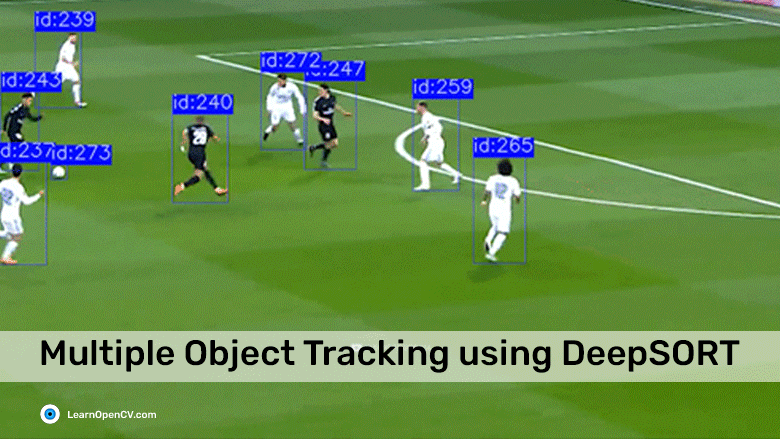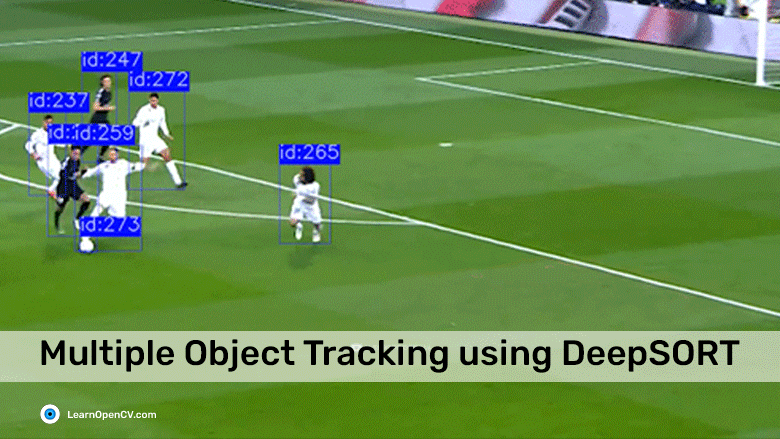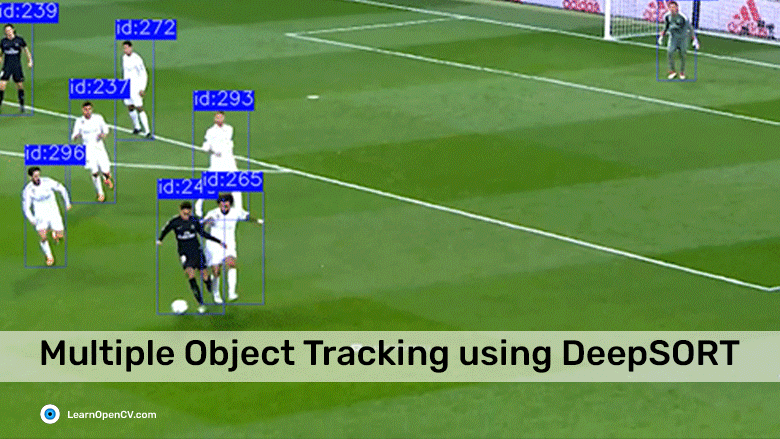 Applications of Object Tracking
Applications of Object Tracking
- Surveillance use cases: With the help of sophisticated algorithms that are capable of real-time tracking of objects in a video, businesses can significantly enhance their security departments [1].
- Retail market: A greatly innovative practical application of object tracking in the retail industry can be seen in Amazon Go stores. Amazon has created an amalgamation of various computer vision and artificial intelligence processes to introduce a cashier-less checkout system for their supermarket:
- Autonomous driving: self-driving cars are perhaps the most well-known application of AI-driven object detection and tracking. Since you have to keep track of the road and the objects surrounding you, object detection is very important for the advance of this industry [1].
2.2. Action Recognition
Action recognition is the task of identifying when a person in an image or video is performing a given action. It belongs to a list of tasks that can only be performed on a sequence of images. It is very similar to how we can not understand a sentence from just one word, we cannot also recognize the action from one image. Computer vision algorithms can be trained to recognize a variety of actions, from running and sleeping to drinking, falling, or riding a bike [1]. Applications of action recognition:
Applications of action recognition:
- Surveillance: One of the areas of applications of action recognition is the surveillance industry, such as detecting suspicious or abnormal behavior
- Human-Computer Interaction: Another area of application of action recognition is human-computer interaction, such as gesture-controlled devices.
2.3. Motion Estimation
Motion estimation examines the movement of objects in an image sequence to try to obtain vectors representing the estimated motion. This is important in the application that focuses on estimating the actual velocity or trajectory that is captured in videos. Motion estimation is very useful in different industries such as traffic management to estimate the velocity of cars and also in entertainment industries to capture motion in order to apply visual effects to it or to overlay 3D information on TV streams or broadcasting.
Motion estimation is very useful in different industries such as traffic management to estimate the velocity of cars and also in entertainment industries to capture motion in order to apply visual effects to it or to overlay 3D information on TV streams or broadcasting.
3. Content-aware Image Editing
Computer vision algorithms are not only used to analyze the content of the images, as shown before but also to improve the quality and the content of the images. Nowadays basic image processing and enhancement tools such as filtering with smarter methods that use prior knowledge of the image content to improve the visual quality of the image. For example, if a model is trained to know what a bird typically looks like, then it can apply this knowledge in order to replace noisy pixels with coherent ones in bird pictures. This concept can be applied to image restoration or resolution enhancement. The figure below shows restored pixels using Nividia content-aware filling tool [1].a
4. Scene Reconstruction
Scene reconstruction is the process of reconstructing a 3D digital version of a real-world object from pictures or scans of the object. It is a very complex problem with a lot of research history, open problems, and possible solutions. In this process, the correspondences between two images of scenes from different viewpoints order to derive the distance of each visualized element. More advanced methods take several images and match their content together in order to obtain a 3D model of the target scene [1]. Application
Application
Special Effects and 3D Modeling: There’s a area of computer vision people know a little bit less about. It’s used a lot in special effects, everything from capturing the shape of somebody, so you take the scan of somebody’s face, whether it’s laser or otherwise. You build models, and then you can make lots of these people, and you can light them from different sides and different directions because you have a full 3D model.
Likewise, motion capture, so if you saw Pirates of the Caribbean, the one with the, the guy with all the weird things on his face, and of course, you know, that’s all CGI, but the question is, how do they know exactly where to put his face and everything? Well, that, there are these markers that are being worn that are being tracked by these cameras. And they have to figure out the three-dimensional geometry, and that’s also a form of computer vision. Another area that’s become but this is a shot from Google Earth actually, this is from Microsoft’s Virtual Earth. Google Earth is yet another version of it. Where basically, they can take imagery, so here’s imagery, aerial imagery. But also, they can use that to figure out the models of the buildings. Put those three-dimensional models in there, and then you can fly around them however you want. So that’s a structure for motion method of using lots of images, a sequence, to recover the three-dimensional structure. We’ll talk only a little bit about that. We’ll focus mostly on a couple of images.
Another area that’s become but this is a shot from Google Earth actually, this is from Microsoft’s Virtual Earth. Google Earth is yet another version of it. Where basically, they can take imagery, so here’s imagery, aerial imagery. But also, they can use that to figure out the models of the buildings. Put those three-dimensional models in there, and then you can fly around them however you want. So that’s a structure for motion method of using lots of images, a sequence, to recover the three-dimensional structure. We’ll talk only a little bit about that. We’ll focus mostly on a couple of images.
5- Games
5.1- Vision Based Interaction
Something else that has really changed lately, is the pushing of computer vision down into video games.So one of the first places to do that was the Nintendo Wii. The remote control, there’s actually a camera system built right into here, that tracks the two dots that are from the sensor bar and reports that information. But the real game-changer in terms of computer vision being involved in games was the Microsoft Kinect. The Microsoft Kinect is a depth sensor. And what I mean by that, is it can produce a scene like this, that is, it can, it can produce an image like this from a scene.
But the real game-changer in terms of computer vision being involved in games was the Microsoft Kinect. The Microsoft Kinect is a depth sensor. And what I mean by that, is it can produce a scene like this, that is, it can, it can produce an image like this from a scene. And this is a depth image, right? So darker is farther away. And brighter is closer. And gray here is sort of in between.
And this is a depth image, right? So darker is farther away. And brighter is closer. And gray here is sort of in between.
So from a technological perspective. From a raw technology perspective, most people think that what was important about the Kinect was that it created a depth image.
The important thing about a Kinect is that it can produce skeletal descriptions. Using a combination of machine learning techniques applied to computer vision, the folks at Microsoft and this came out of Microsoft Cambridge in the UK. Were able to recover the skeleton geometry of people from the depth image. And by the way, they do it instantaneously. Every frame, they do it differently. They don’t even track it, they just do it one frame at a time. It’s that robust. Right? And because they can get the skeleton information, you can build really cool user interfaces. So you could you know, do driving games and go like this, to steer your car.
Right? And because they can get the skeleton information, you can build really cool user interfaces. So you could you know, do driving games and go like this, to steer your car.
Much more interesting of course, is playing with robots. And here you see, this is Simon, in Andrea Tomas’ lab, here at Georgia Tech. And the reason that Simon is waving to this student, is that behind Simon over here, there’s a Kinect that’s looking at the student waving. And is getting back the depth information. Also the skeleton information is then interpreting the skeleton information, in terms of what the human is doing.And that in turn, allows the robot a decision about what the robot wants to do.
So even though the Kinect was sort of promoted and invented as a way of impacting games. And early on, there was some uncertainty at Microsoft whether they wanted to open up that, system and let people use it. They quickly realized that this is something that everybody wants to use. And it has really revolutionized the way people think about depth imaging, and computer vision applied to depth imagery.
Please Follow coursesteach to see latest updates on this story
If you want to learn more about these topics: Python, Machine Learning Data Science, Statistic For Machine learning, Linear Algebra for Machine learning Computer Vision and Research
Then Login and Enroll in Coursesteach to get fantastic content in the data field.
Stay tuned for our upcoming articles where we will explore specific topics related to Computer Vision in more detail!
Remember, learning is a continuous process. So keep learning and keep creating and Sharing with others!💻✌️
References
1- Overview of Computer Vision Tasks & Applications
2-Introduction of Computer Vision
3-What Is Computer Vision — A very Simple Explanation (Episode 2 | CVFE)
























































