BERT Nedir?

Transformatörlerden Çift Yönlü Kodlayıcı Temsillerinin kısaltması olan BERT, doğal dil işleme için bir Makine Öğrenimi (ML) modelidir. Google AI Language'deki araştırmacılar tarafından 2018 yılında geliştirilmiştir ve duygu analizi ve adlandırılmış varlık tanıma gibi en yaygın dil görevlerinden 11'den fazlasına İsviçre çakısı çözümü olarak hizmet vermektedir.
Dilin bilgisayarlar tarafından 'anlaşılması' tarihsel olarak zor olmuştur. Elbette, bilgisayarlar metin girdilerini toplayabilir, saklayabilir ve okuyabilir ancak temel dil bağlamından yoksundurlar.
Böylece Doğal Dil İşleme (NLP) ortaya çıktı: bilgisayarların metin ve sözlü kelimeleri okumasını, analiz etmesini, yorumlamasını ve bunlardan anlam çıkarmasını amaçlayan yapay zeka alanı. Bu uygulama, bilgisayarların insan dilini 'anlamasına' yardımcı olmak için dilbilim, istatistik ve Makine Öğrenimini birleştirir.
Bireysel NLP görevleri geleneksel olarak her bir özel görev için oluşturulan bireysel modeller tarafından çözülmüştür. Ta ki - BERT!
BERT, en yaygın NLP görevlerinden 11'den fazlasını çözerek (ve önceki modellerden daha iyi) NLP alanında devrim yarattı ve onu tüm NLP işlemlerinin krikosu haline getirdi.
1. BERT ne için kullanılır?
BERT çok çeşitli dil görevlerinde kullanılabilir: Bir filmin yorumlarının ne kadar olumlu veya olumsuz olduğunu belirleyebilir. (Duygu Analizi) Sohbet robotlarının sorularınızı yanıtlamasına yardımcı olur. (Soru cevaplama) E-posta yazarken metninizi tahmin eder (Gmail). (Metin tahmini) Sadece birkaç cümle girdisi ile herhangi bir konu hakkında bir makale yazabilir. (Metin oluşturma) Uzun yasal sözleşmeleri hızlıca özetleyebilir. (Özetleme) Çevreleyen metne dayanarak birden fazla anlamı olan kelimeleri ('banka' gibi) ayırt edebilir. (Çok anlamlılık çözümü) Daha birçok dil/NLP görevi ve bunların her birinin arkasında daha fazla ayrıntı vardır.
Eğlenceli Gerçek: NLP (ve muhtemelen BERT) ile neredeyse her gün etkileşime giriyorsunuz! Google Translate, sesli asistanlar (Alexa, Siri, vb.), sohbet botları, Google aramaları, sesle çalışan GPS ve daha fazlasının arkasında NLP vardır.
1.1 BERT Örneği
BERT, Kasım 2020'den bu yana neredeyse tüm aramalar için Google'ın (İngilizce) sonuçları daha iyi ortaya çıkarmasına yardımcı oluyor. İşte BERT'in Google'ın aşağıdaki gibi belirli aramaları daha iyi anlamasına nasıl yardımcı olduğuna dair bir örnek: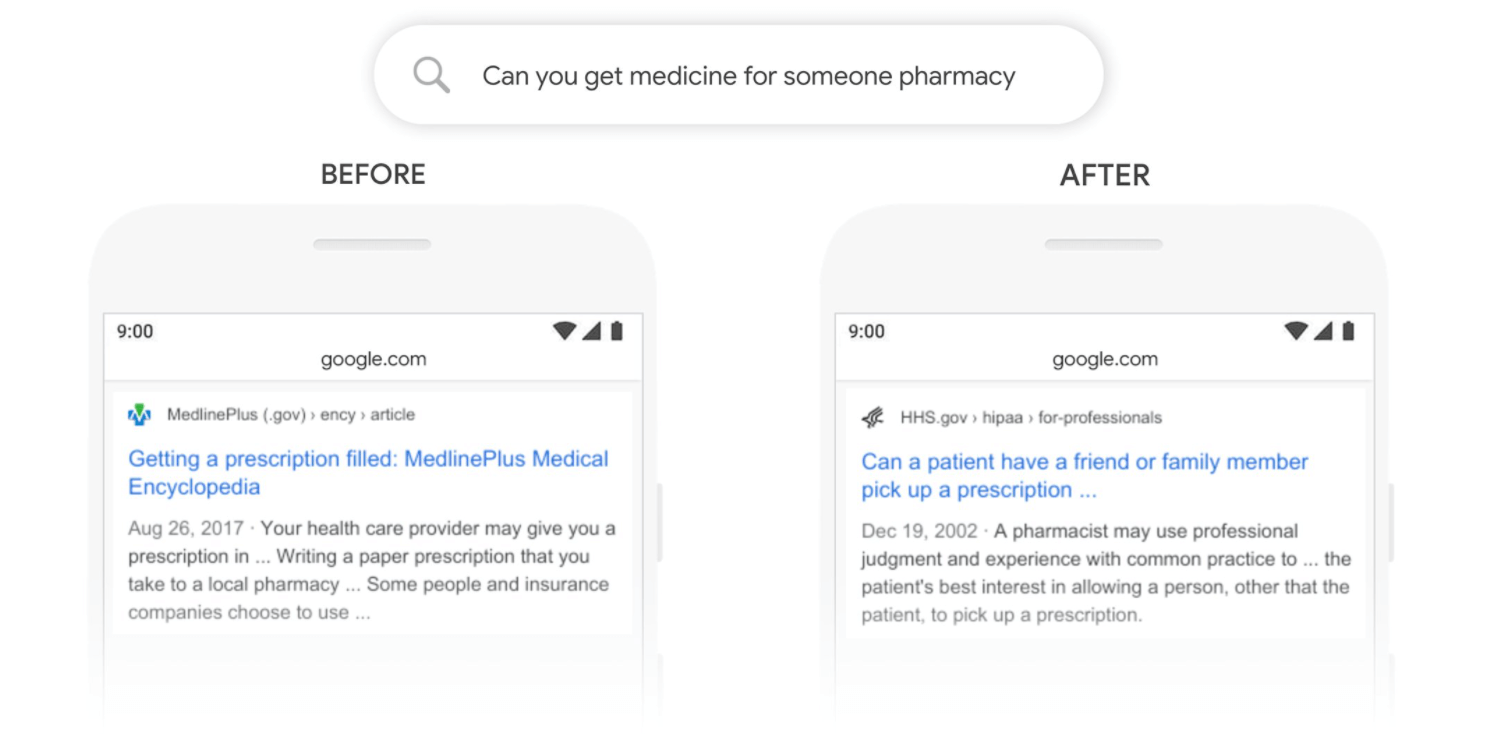
BERT Google Arama Örneği Kaynak BERT öncesi Google, bir reçetenin doldurulmasıyla ilgili bilgileri ortaya çıkarıyordu. BERT sonrası Google, "birisi için" ifadesinin bir başkası için reçete almakla ilgili olduğunu anlıyor ve arama sonuçları artık buna yanıt vermeye yardımcı oluyor.
2. BERT Nasıl Çalışır?
BERT aşağıdakilerden yararlanarak çalışır:
2.1 Büyük miktarda eğitim verisi
BERT'in devam eden başarısına 3,3 Milyar kelimeden oluşan devasa bir veri seti katkıda bulunmuştur.
BERT özellikle Wikipedia (~2,5 milyar kelime) ve Google'ın BooksCorpus'u (~800 milyon kelime) üzerinde eğitilmiştir. Bu büyük bilgi veri kümeleri, BERT'in yalnızca İngilizce diline değil, aynı zamanda dünyamıza ilişkin derin bilgisine de katkıda bulundu! 🚀
Bu kadar büyük bir veri kümesi üzerinde eğitim uzun zaman alır. BERT'in eğitimi yeni Transformer mimarisi sayesinde mümkün oldu ve TPU'lar (Tensor Processing Units - Google'ın büyük makine öğrenimi modelleri için özel olarak geliştirdiği devre) kullanılarak hızlandırıldı. -64 TPU, 4 gün boyunca BERT'i eğitti.
Not: BERT'i daha küçük hesaplama ortamlarında (cep telefonları ve kişisel bilgisayarlar gibi) kullanmak için daha küçük BERT modellerine olan talep artmaktadır. Mart 2020'de 23 küçük BERT modeli piyasaya sürülmüştür. DistilBERT, BERT'in daha hafif bir versiyonunu sunar; BERT'in performansının %95'inden fazlasını korurken %60 daha hızlı çalışır.
2.2 Maskelenmiş Dil Modeli Nedir?
MLM, bir cümledeki bir kelimeyi maskeleyerek (gizleyerek) ve BERT'i maskeli kelimeyi tahmin etmek için örtülü kelimenin her iki tarafındaki kelimeleri çift yönlü olarak kullanmaya zorlayarak metinden çift yönlü öğrenmeyi sağlar / güçlendirir. Bu daha önce hiç yapılmamıştı!
Eğlenceli Bilgi: İnsan olarak bunu doğal olarak yaparız!
Maskelenmiş Dil Modeli Örneği:
Glacier Ulusal Parkı'nda kamp yaparken arkadaşınızın sizi aradığını ve telefonunun kesilmeye başladığını düşünün. Arama kesilmeden önce duyduğunuz son şey:
Friend: “Dang! I’m out fishing and a huge trout just [blank] my line!”
Can you guess what your friend said??
Doğal olarak, eksik kelimeden önce ve sonra gelen kelimeleri bağlam ipuçları olarak değerlendirerek (balıkçılığın nasıl işlediğine dair tarihsel bilginize ek olarak) eksik kelimeyi tahmin edebilirsiniz. Arkadaşınızın 'kırıldı' dediğini tahmin ettiniz mi? Biz de öyle tahmin ettik ama biz insanlar bile bu yöntemlerin bazılarında hataya yatkınız.
Not: Bu nedenle bir dil modelinin performans puanlarıyla "İnsan Performansı" karşılaştırmasını sık sık görürsünüz. Ve evet, BERT gibi yeni modeller insanlardan daha doğru olabilir! 🤯
Yukarıdaki [boş] kelimeyi doldurmak için yaptığınız çift yönlü metodoloji, BERT'in son teknoloji ürünü doğruluğa nasıl ulaştığına benzer. Eğitim sırasında tokenize edilmiş kelimelerin rastgele %15'i gizlenir ve BERT'in görevi gizli kelimeleri doğru tahmin etmektir. Böylece, modele doğrudan İngilizce dilini (ve kullandığımız kelimeleri) öğretir. Ne kadar güzel değil mi?
BERT'in maskeleme tahminleri ile oynayın:
2.3 Sonraki Cümle Tahmini Nedir?
NSP (Sonraki Cümle Tahmini), belirli bir cümlenin önceki cümleyi takip edip etmediğini tahmin ederek BERT'in cümleler arasındaki ilişkileri öğrenmesine yardımcı olmak için kullanılır.
Sonraki Cümle Tahmin Örneği:
- Paul alışverişe gitti. Yeni bir gömlek aldı. (doğru cümle çifti)
- Ramona kahve yaptı. Vanilyalı dondurma külahları satılık. (yanlış cümle çifti)
Eğitimde, BERT'in bir sonraki cümle tahmin doğruluğunu artırmasına yardımcı olmak için %50 doğru cümle çiftleri %50 rastgele cümle çiftleriyle karıştırılır.
Eğlenceli Bilgi: BERT aynı anda hem MLM (%50) hem de NSP (%50) üzerinde eğitilir.
2.4 Transformatörler
Transformer mimarisi, makine öğrenimi eğitimini son derece verimli bir şekilde paralelleştirmeyi mümkün kılar. Büyük ölçekli paralelleştirme, BERT'in büyük miktarda veri üzerinde nispeten kısa bir süre içinde eğitilmesini mümkün kılar.
Transformatörler, kelimeler arasındaki ilişkileri gözlemlemek için bir dikkat mekanizması kullanır. İlk olarak popüler 2017 Attention Is All You Need makalesinde önerilen bir kavram, Transformatörlerin tüm dünyada NLP modellerinde kullanılmasına yol açtı.
2.4.1 Transformatörler nasıl çalışır?
Transformers, ilk olarak bilgisayarla görme modellerinde görülen güçlü bir derin öğrenme algoritması olan dikkatten yararlanarak çalışır.
-Biz insanların bilgiyi dikkat yoluyla işlememizden pek de farklı değil. Tehdit oluşturmayan veya bizden bir yanıt gerektirmeyen sıradan günlük girdileri unutma/görmezden gelme konusunda inanılmaz derecede iyiyiz. Örneğin, geçen Salı eve gelirken gördüğünüz ve duyduğunuz her şeyi hatırlayabiliyor musunuz? Elbette hayır! Beynimizin hafızası sınırlı ve değerlidir. Hatırlamamıza, önemsiz girdileri unutma becerimiz yardımcı olur.
Benzer şekilde, Makine Öğrenimi modellerinin sadece önemli olan şeylere nasıl dikkat edeceklerini ve alakasız bilgileri işleyerek hesaplama kaynaklarını nasıl boşa harcamayacaklarını öğrenmeleri gerekir. Dönüştürücüler, bir cümledeki hangi kelimelerin daha fazla işlem için en kritik olduğuna işaret eden diferansiyel ağırlıklar oluşturur. ![]()
Bir transformatör bunu, genellikle kodlayıcı olarak adlandırılan bir transformatör katmanları yığını aracılığıyla bir girdiyi art arda işleyerek yapar. Gerekirse, hedef çıktıyı tahmin etmek için başka bir dönüştürücü katman yığını - kod çözücü - kullanılabilir. Ancak -BERT bir kod çözücü kullanmaz. Transformatörler, milyonlarca veri noktasını verimli bir şekilde işleyebildikleri için denetimsiz öğrenme için benzersiz bir şekilde uygundur.
Eğlenceli Bilgi: Google, 2011 yılından bu yana eğitim verilerini etiketlemek için reCAPTCHA seçimlerinizi kullanıyor. Google Books arşivinin tamamı ve New York Times kataloğundaki 13 milyon makale, reCAPTCHA metni giren kişiler aracılığıyla yazıya döküldü / dijitalleştirildi. Şimdi reCAPTCHA bizden Google Street View görüntülerini, araçları, stop lambalarını, uçakları vb. etiketlememizi istiyor. Google'ın bu çabaya katılımımızdan bizi haberdar etmesi güzel olurdu (çünkü eğitim verilerinin gelecekte ticari bir amacı olması muhtemeldir) ama konudan sapıyorum...
3. BERT model boyutu ve mimarisi
İki orijinal BERT modeli için mimariyi inceleyelim: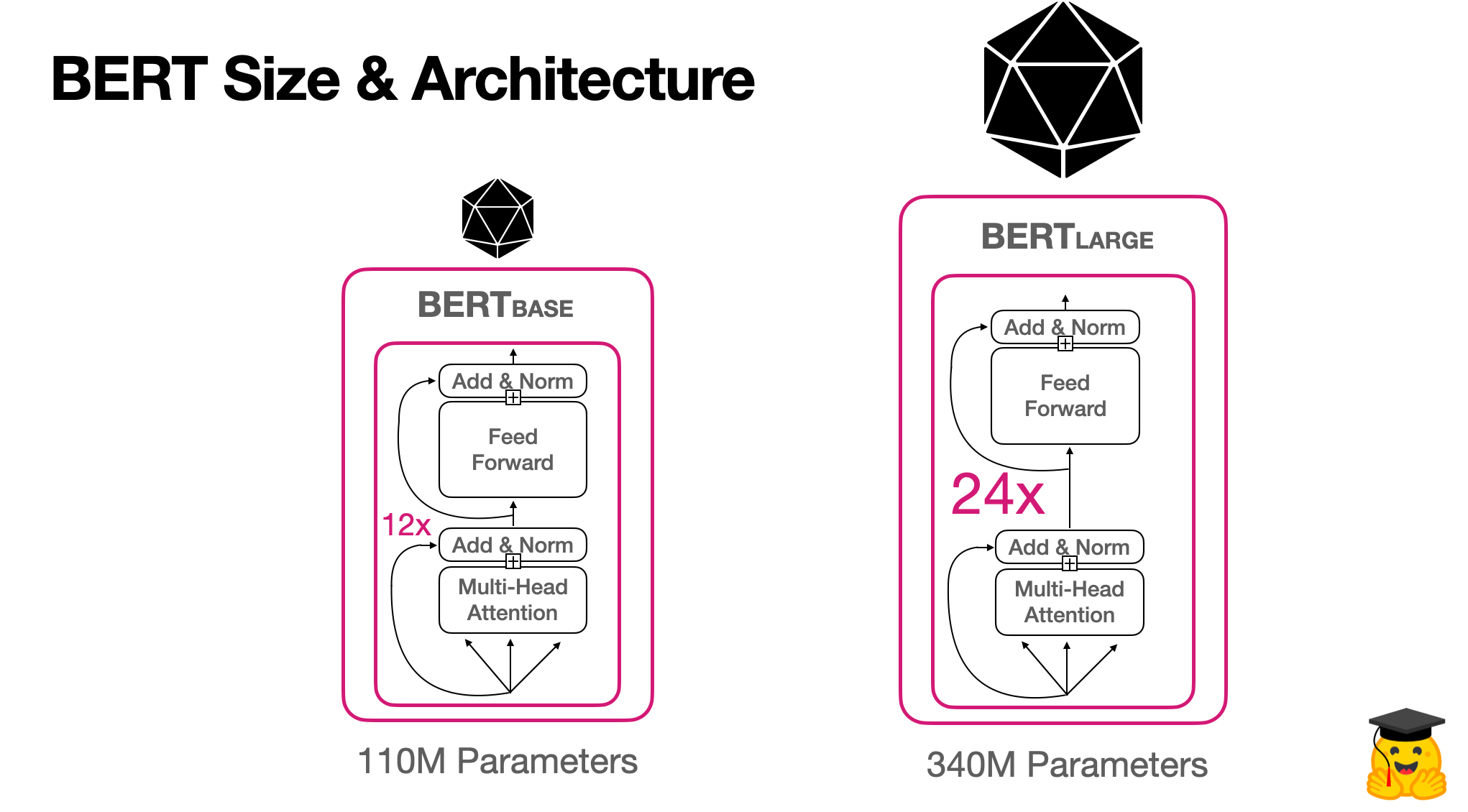
4. BERT'in ortak dil görevlerindeki performansı
BERT, 11 yaygın NLP görevinde son teknoloji ürünü doğruluğu başarıyla elde ederek önceki en iyi NLP modellerinden daha iyi performans gösterdi ve insanlardan daha iyi performans gösteren ilk model oldu!
Kaynakça
https://huggingface.co/blog/bert-101#241-how-do-transformers-work
https://arxiv.org/pdf/1810.04805.pdf






















































