Simplified Machine Learning

Concept Learning
Inferring a boolean-valued function from training examples and acquiring the definition of a general category given a sample of positive and negative training examples of the category.
for example, I want to know whether I would enjoy going out (yes/no boolean value) if the sky is sunny, the temperature is warm, humid is high…
Concept Learning is a type of Supervised Learning.Photo by Avel Chuklanov on Unsplash
So, What is Supervised Learning?
Supervised Learning algorithms build a mathematical model of dataset that contains both inputs and desired outputs.
- typical supervised learning techniques: concept learning, classification and regression
- compared to unsupervised learning, where inputs are known but we want to discover the outputs or underlying patterns
Classification
output data is discrete categories — to identify which category the new observation belongs to
- e.g. Decision Tree Learning is a common classification technique (will be discussed in future articles)
Regression
output data is real numbers — estimating relationship among variables
1. linear regression
- the linear approach to model the relationship between the dependent variable (scalar response) and one or more independent variables (explanatory variables)
- simple linear regression: when having only one independent variable hence Y = w0 + w1x (can be simply thought of as linear algebra learnt in high school Y = f(X) = a + bX)
2. ordinal regression
- a type of regression analysis used for predicting an ordinal variable (where the output variables have ordered categories), therefore, can be thought of as between regression and classification
- by assigning numbers to ordinal categories, classification problem has been transformed into regression analysis (General Linear Model)
- popularly used in social science (e.g. strongly agree, agree, neutral, disagree, strongly disagree*)
3. logistic regression
- uses a logistic function to model a binary dependent variable (e.g. predicting the risk of developing a disease)
- for examples, predicting the risk of developing a disease; sigmoid function using in Artificial Neural Network (ANN) is an example of using logistic regression model
How to Represent Concept Learning?
Data representation
- using attribute-value pairs
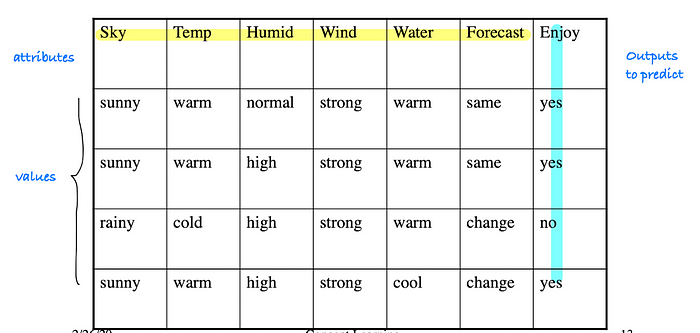
Hypothesis Representation
- using conjunction of constraints on attributes
- ? — accept any value for the attribute
- 0 — no value acceptable for the attribute
- most general hypothesis <?,?,?,?,?,?>
- most specific hypothesis <0,0,0,0,0,0>
Notation:
- X: represents all instances used to define the concept
- c: the boolean-valued target concept we denote to learn c: X → {0, 1} (target function maps instance into 0 or 1)
- H: the set of all possible hypotheses (hypothesis space) that learner may consider to estimate target concept c
- there might be a difference in the actual value c(x) and the predicted value h(x), but the aim of the learning algorithm is to minimize the error
Inductive Learning Hypothesis:
- Any hypothesis found to approximate the target function well over a sufficiently large set of training examples will also approximate the target function well over other unobserved examples.
- this is the fundamental assumption of inductive learning
Hypothesis Search Space
- concept learning as search: same for all learning algorithms, concept learning can be thought of as search through hypothesis space and find the appropriate inductive hypothesis
Calculate Size of Search Space — three methods

General-to-Specific Ordering
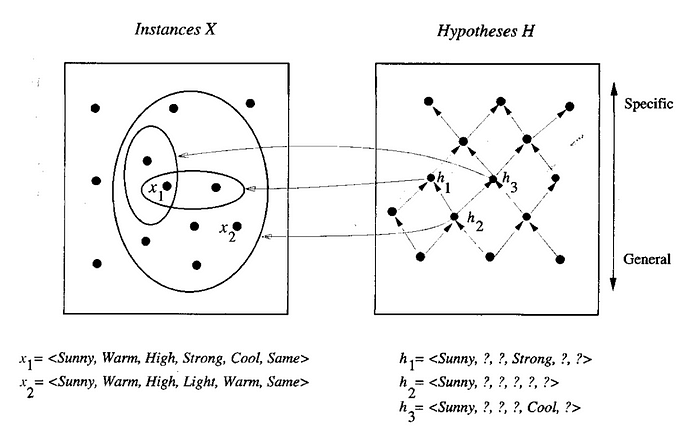
- start with a general hypothesis space and work all the way through to the specific or vice versa
- hypothesis arranged in a partial ordering (reflexive, antisymmetric & transitive)
Partially ordered set
In mathematics, especially order theory, a partially ordered set (also poset) formalizes and generalizes the intuitive…
Find-S Algorithm

Properties
- finding a maximally specific hypothesis:
- begin with the most specific possible hypothesis (h ← <0,0,0,0,0,0>)and generalize this hypothesis each time it fails to meet the goal
- ignores every negative example
Inductive bias of Find-S
- new instances are classified only in the case where all members of the current version space agree on the classification, otherwise, the system refuses to classify the new instance (same as candidate elimination)
- and additionally, all instances are assumed to be negative instances until the opposite is entailed by its other knowledge
List-then-Eliminate Algorithm

Process:
- start with version space = all hypothesis
- go through all hypothesis, and test the hypothesis for each training examples and find those that satisfy
- output the updated version space
Problem:
- it requires exhaustively enumerating all hypotheses in hypothesis space
Candidate Elimination Algorithm
An updated version of list-then-eliminate algorithm, employing a more compact representation of version space. Find all descriable hypotheses that are consistent with the observed training examples.
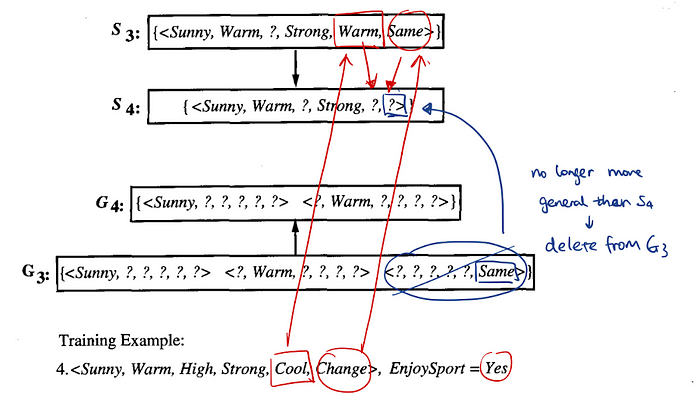
Compacted Representation of Version Space:
- general specific boundaries:
- general boundary G: the maximally general hypothesis consistent with training data D
- specific boundary S: the minimally general hypothesis consistent with training data D
Process:
- for each training examples: update S and G until consistent with training example; check S and G, remove hypothesis from G that is less general than another hypothesis in S and vice versa
- the boundaries will converge if there are no errors in the training examples
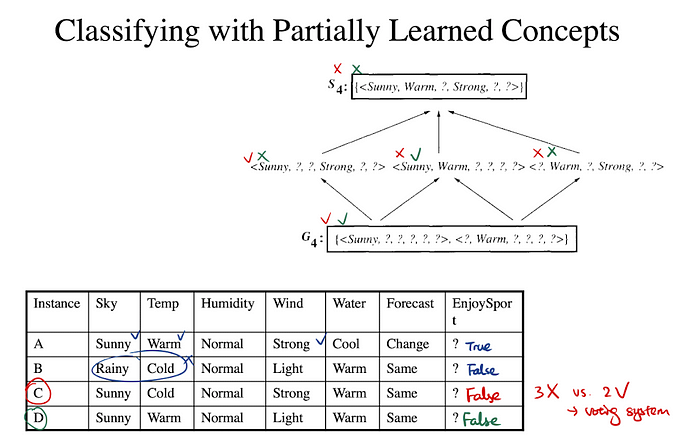
Partially Learned Concepts
- when training examples used up before the boundary convergence
- new instance satisfies all s → positive
- new instance satisfies none of g → negative
- otherwise, use voting
Candidate Elimination vs. Find-S:
- in find-s algorithm only find hypotheses that satisfy with training examples, hence only consider positive training example
- in candidate elimination algorithm, we need to find all consistent hypothesis — version space, hence h(x) = c(x) consider both positive and negative training examples
Inductive Bias
Inductive bias is the set of assumptions that, together with the training data, deductively justify the classifications assigned by the learner to future instances. Every learner has an inductive bias.
Simply said, it is the assumptions that are used to make generalization beyond observed data. If a learner is unbiased, it is completely unable to generalize beyond the unobserved examples — it is just a database.
Inductive vs. Deductive system
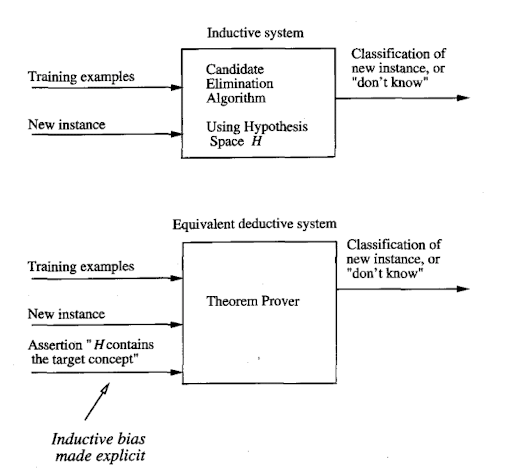
- deductive reasoning: general principle → special cases
- inductive reasoning: special cases → general principle
Two types of Inductive Biases
- Preference Bias: incompletely search through a complete hypothesis space, therefore inductive bias introduced by search strategy bias
- (e.g. ID3 algorithm — it uses heuristic search to guide in the search space which increases the chance of taking leaps in steps)
- Restriction Bias: complete search through an incomplete hypothesis space, therefore, inductive bias introduced by hypothesis space
- (e.g. candidate-elimination algorithm searches through version space which is a subset of the whole hypothesis space)
- Preference bias is more desirable because of the increase in computing power
A note from AI In Plain English
We are always interested in helping to promote quality content. If you have an article that you would like to submit to any of our publications, send us an email at submissions@plainenglish.io with your Medium username and we will get you added as a writer.









































