Computer Vision and Reinforcement Learning for Autonomous Convoy Systems

In the rapidly evolving landscape of autonomous driving, the integration of cutting-edge technologies such as Computer Vision and Reinforcement Learning has become instrumental in shaping the future of transportation. This article explores the transformative potential of these technologies specifically within the context of Autonomous Convoy Systems, aiming to revolutionize the way vehicles move in synchronized harmony.
Understanding Autonomous Convoy Systems:
Autonomous Convoy Systems, often referred to as platooning, involve a group of vehicles moving in close proximity, leveraging advanced technologies to enhance efficiency, reduce fuel consumption, and improve overall traffic flow. The synergy between Computer Vision and Reinforcement Learning plays a pivotal role in realizing the full potential of these convoy systems.:quality(70)/cloudfront-us-east-1.images.arcpublishing.com/archetype/MIWKCUHIQZCOJHN4YEZSGQRIOM.jpeg)
Role of Computer Vision:
Computer Vision acts as the eyes of autonomous convoy systems, enabling vehicles to perceive and interpret the dynamic environment. Through real-time object detection, lane tracking, and obstacle recognition, Computer Vision ensures that vehicles within the convoy can navigate safely and respond to changing road conditions with precision.
Harnessing Reinforcement Learning for Intelligent Decision-Making:
Reinforcement Learning empowers autonomous vehicles within the convoy to make intelligent decisions by learning from experience. This adaptive learning process allows vehicles to optimize their driving behavior, respond to diverse scenarios, and continually improve performance over time. From adaptive cruise control to strategic convoy formation, Reinforcement Learning enhances the decision-making capabilities of each vehicle.
Benefits of Integration:
The seamless integration of Computer Vision and Reinforcement Learning in Autonomous Convoy Systems brings forth numerous benefits, including:
- Improved Fuel Efficiency: Through precise control and synchronization, convoy systems minimize aerodynamic drag, leading to significant fuel savings.
- Enhanced Safety: Real-time monitoring and decision-making capabilities contribute to safer navigation and reduced collision risks.
- Traffic Optimization: Convoy systems optimize traffic flow, reducing congestion and improving overall road network efficiency.
Challenges and Future Prospects:
While the potential benefits are immense, challenges such as regulatory considerations, public acceptance, and the need for standardized communication protocols must be addressed. Looking ahead, the continued advancement of these technologies holds promise for even greater innovation in autonomous convoy systems.
Segmentation Camera
The simulator's segmentation camera was utilized to extract essential information required for generating the environmental states that serve as inputs for the reinforcement learning agents. The segmentation camera efficiently categorizes individual objects within an RGB image using distinct tags, enabling the mapping of each tag to the corresponding object as outlined in CARLA’s documentation. Upon simulation initiation, all environmental objects are assigned specific tags. During image retrieval, the tag information is encoded in the red channel, signifying that pixels with a red value of ‘10’ correspond to the object identified with the tag ‘10’. In our specific use case, the significance of tag ‘10’ is paramount as it designates the leader.
With a single line of code, the segmentation image undergoes manipulation to transform it into an image exclusively featuring the identified leader.
leader = (sem_camera==10)*1

Utilizing this ultimate binary matrix, where the value 1 signifies the presence of the leader, we can now construct the states for our agents!
Steer Agent
For the Steer Agent, the state is defined by two binary features named 'left' and 'right.' If 'left' is 1 while 'right' is 0, it indicates that the agent is not aligned with the leader, and the leader is positioned on the left of the agent. Conversely, if 'right' is 1 and 'left' is 0, the agent is not aligned with the leader, and the leader is on the right. When both 'left' and 'right' are 0, it signifies that the agent is aligned with the leader.
Applying matrix manipulation to the processed image allows us to effortlessly extract the relevant information, adhering to the following rules: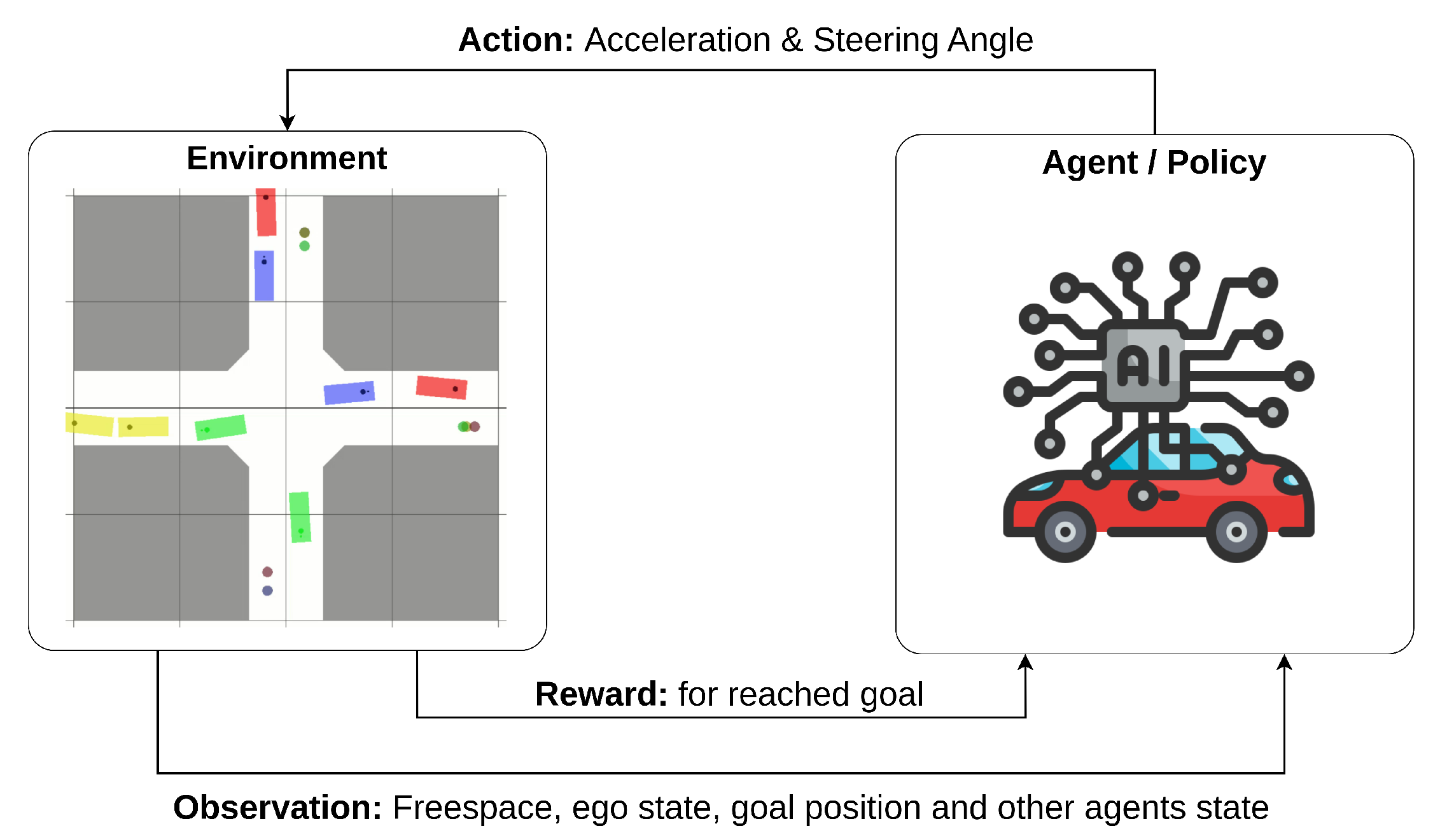
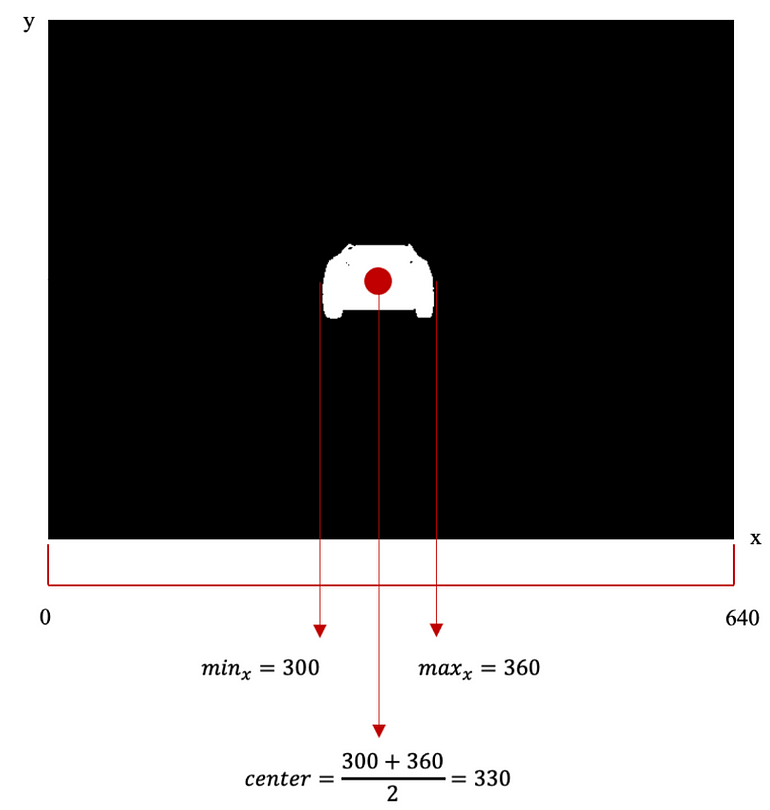
center_leader = int((min(np.where(leader)[1])+max(np.where(leader)[1]))/2)
If the center of the leader is on a pixel where the x coordinate is lower than 300 then ‘left’ is 1 and ‘right’ is 0;
leader_left = (300 > pixel_leader)*1
If the center of the leader is on a pixel where the x coordinate is higher than 340 then ‘left’ is 0 and ‘right’ is 1;
leader_right = (340 < pixel_leader)*1
Finally, If the center of the leader is on a pixel where the x coordinate is between 300 and 340 then ‘left’ is 0 and ‘right’ is 0.
aligned_with_leader = (300 <= pixel_leader) & (340 >= pixel_leader)*1
Following the extraction of the state, our PPO algorithm is tasked with selecting one of the following actions:
- Move straight
- Turn left
- Turn right
The decision-making process hinges on identifying the action with the highest probability, calculated through the output layer utilizing a softmax activation function.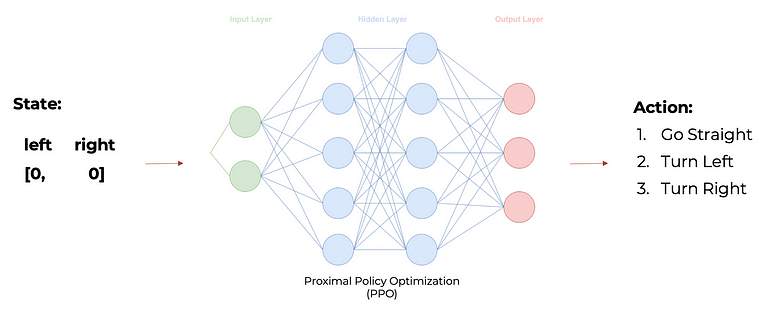
REWARD MECHANISM
The reward function is composed by 4 components:
- If collision happened then reward -10
if len(self.collision_hist) != 0: reward_steer += -10
- If segmented image does not have the tag 10 then reward -10
elif sum(state[:3]) == 0: reward_steer += -10
- If ‘left’ and ‘right’ equal to 0 then reward +5, otherwise -5
if state[0] == 1: reward_steer += 5 else: reward_steer -= 5
- Guiding decision:
If ‘left’ equal to 1 and action is either going straight or right then reward -5, otherwise +5
If ‘right’ equal to 1 and action is either going straight or left then reward -5, otherwise +5
If ‘right’ and ‘left’ equal to 0 and action is not going straight then reward -5, otherwise +5
if (state[1] == 1) & (action_steer > 0): reward_steer -= 5 elif (state[2] == 1) & (action_steer < 0): reward_steer -= 5 elif (state[1] == 1) & (action_steer < 0): reward_steer += 5 elif (state[2] == 1) & (action_steer > 0): reward_steer += 5 elif (state[0] == 1) & (action_steer != 0.0): reward_steer -= 5 elif (state[0] == 1) & (action_steer == 0.0): reward_steer += 5
From this final component, it becomes evident that a straightforward heuristic could potentially address the problem. When the leader's location is known, determining the appropriate action becomes straightforward, and the action remains consistent for the same state representation.
Nevertheless, it is noteworthy that the PPO algorithm demonstrated its capability to learn and incorporate this heuristic into its decision-making process!
TERMINATION CONDITIONS
The episode concludes under the following circumstances:
- The episode exceeds a duration of 60 seconds.
- The agent experiences a collision.
- The leader is lost, indicated by the absence of tag '10' in the segmented image.
TRAINING PROGRESS:
Significant progress is observed in the training results:
- Around episode 500, a positive drift in episode rewards indicates that the agent commenced learning the expected behavior.
- From episode 650 onward, the cumulative reward has stabilized, suggesting that the model has successfully converged.

Throttle/Break Agent
STATE REPRESENTATION
For this agent, the state is characterized by three features: 'distance,' 'previous distance,' and 'velocity.'
- Distance: This is the prediction derived from Xception.
- Previous Distance: Represents the prediction from the previous state.
- Velocity: Signifies the current speed at which the agent is moving.
While 'velocity' is a direct sensor input available to every car, the extraction of the other features for the state involves utilizing the same segmented image employed in the Steer Agent. This segmented image is fed into Xception to predict the distance, thus creating the comprehensive state representation for the Throttle/Break Agent.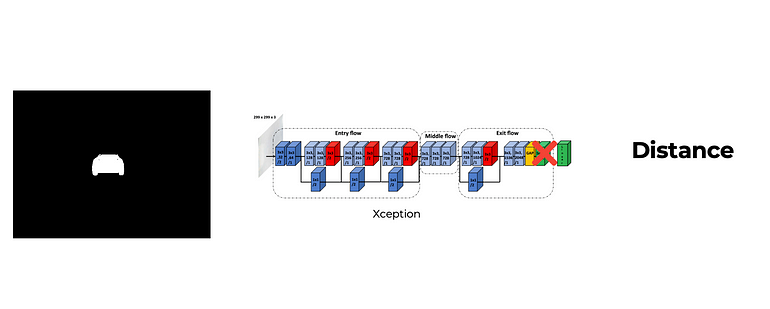 TERMINATION CONDITIONS
TERMINATION CONDITIONS
The episode concludes based on the following criteria:
- The episode duration exceeds 60 seconds.
- The agent experiences a collision.
- The distance to the leader surpasses 25 units.
TRAINING PROGRESS:
Prominent developments are noted in the training results:
- Approximately around episode 430, a positive shift occurs in the episode reward, indicating that the agent has commenced learning the desired behavior.
- Beyond episode 650, the cumulative reward has plateaued, signifying the convergence of the model.

SHAP Values
Upon obtaining an array with explainable features, we leverage it to gain insights into the decision-making process of our agents:
Steer Agent:
The decision to turn left is activated when the state is characterized by 'left' being equal to 1 and 'right' equal to 0. In the context of binary features, a red dot signifies a high feature value, which is represented as 1. The accompanying chart visually depicts the impact on the model output along the x-axis. In this instance, the red dot indicates a substantial impact, exceeding 0.8.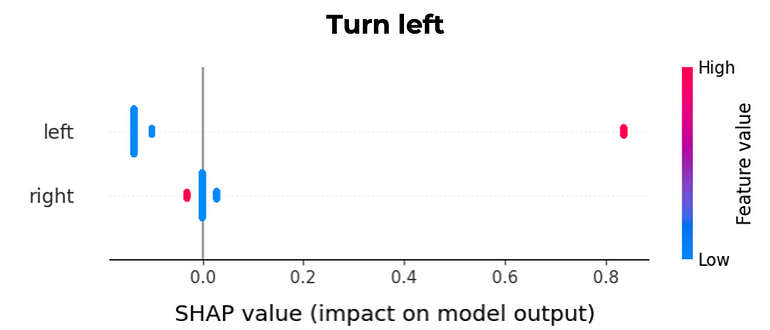
The action to go straight is triggered by the state that does not contain any 1 value for either ‘left’ or ‘right’ because it will decrease the chance of taking this action since the impact on model output is less than -0.8. This means, that a state defined by ‘left’ equal to 0 and ‘right’ equal to 0 will increase the chance of taking this action, since a blue dot means a low feature value which is 0 in a binary feature. Indeed, from the chart it is easily understandable that a 1 value in either ‘left’ or ‘right’ decreases the probability of going straight.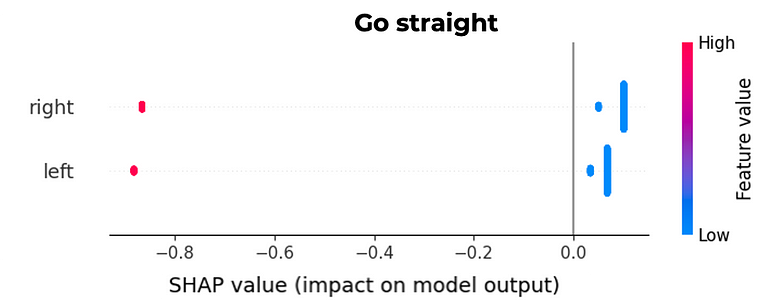
The action to turn right is triggered by the state constituted by ‘left’ equal to 0 and ‘right’ equal to 1. In the chart, it is also possible to verify the impact on model output in the x axis, where in this case the red dot points to an impact of more than 0.8.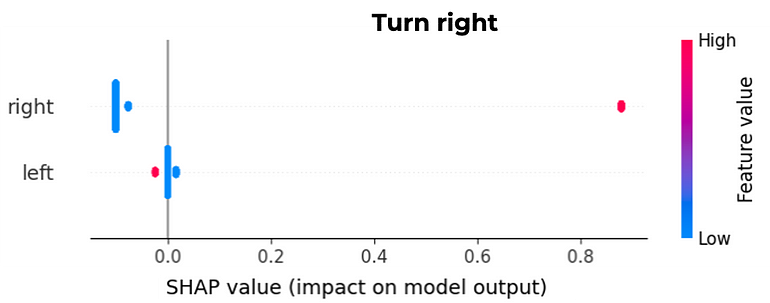
Throttle/Break Agent:
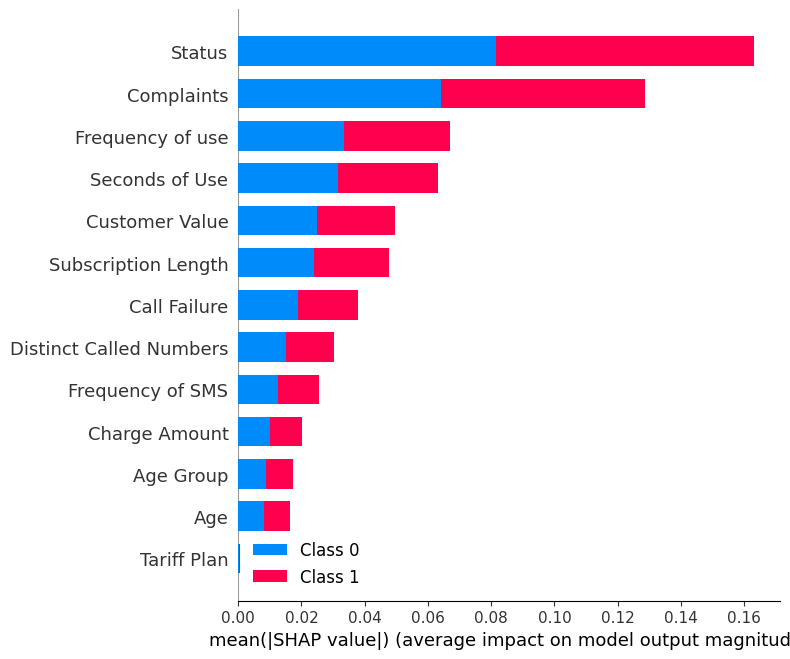
The utilization of the brake by the agent is prominent when the 'velocity' feature attains a high value and/or the 'distance' feature is low. It is noteworthy that the 'previous distance' feature, while significant for the throttle action, does not hold the same level of importance for the brake action. Nevertheless, low values of 'previous distance' also contribute to triggering the brake.These findings align with expectations, as a short 'distance' prompts the need for braking to maintain the desired distance. Additionally, braking is warranted when the 'velocity' is high, ensuring a safety distance is maintained to prevent collisions with the leader.
On the other hand, the throttle is primarily initiated when the 'velocity' is low and/or both the 'distance' and 'previous distance' are high. This logic is coherent, as the agent aims to sustain a distance to the leader within the range of 8 to 10. Thus, if the distance exceeds 10, the throttle is engaged to close the gap.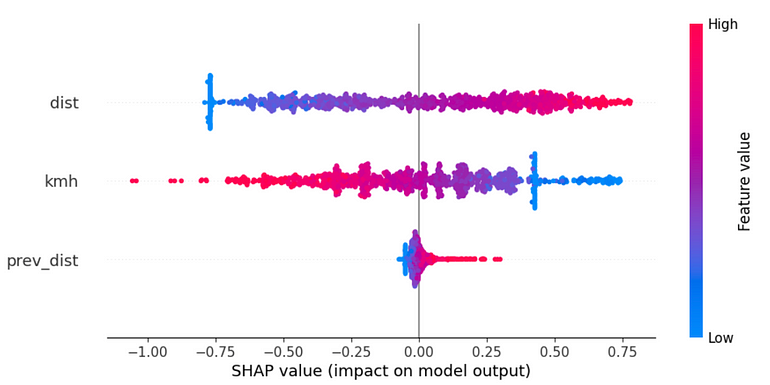
Conclusion:
The convergence of Computer Vision and Reinforcement Learning is poised to redefine the landscape of autonomous convoy systems. As these technologies continue to mature, the transportation industry stands on the brink of a revolution that promises enhanced efficiency, safety, and sustainability in the realm of autonomous driving.