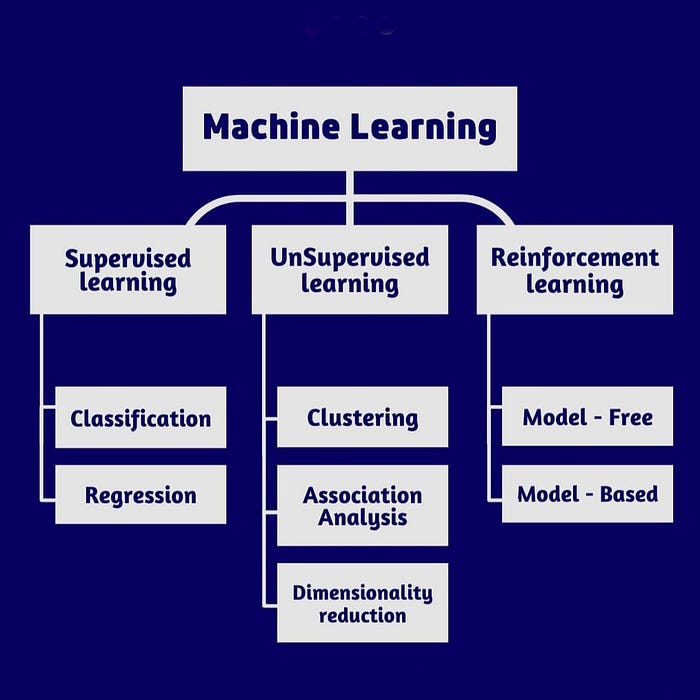
Machine learning (Part 3)-Types of Machine Learning

iduction: Types of Machine Learning
Introduction
Supervised learning and unsupervised learning are two fundamental concepts in machine learning. In supervised learning, we teach a machine learning model to make predictions based on labeled data, while in unsupervised learning, the model discovers patterns and relationships in unlabeled data without any guidance. This blog will explore the key differences between supervised and unsupervised learning algorithms and their applications.
Section
Supervised Learning
Type of Supervised Learning
Semi-supervised learning
Unsupervised Learning
Reinforcement Learning
Comparison
Conclusion
Section 1- Supervised Learning
1.1- Definition
Def: Supervised learning is a type of machine learning in which our algorithms are trained using well-labeled training data, and machines predict the output based on that data.
Def : In supervised learning, the algorithm learns from labeled training data, where input-output pairs are provided. The goal is to map input data to the correct output based on the provided examples. During training, the algorithm adjusts its parameters to minimize the difference between predicted and actual outputs. This enables the model to generalize and make accurate predictions on new, unseen data. Supervised learning is commonly used for tasks such as classification and regression in various fields like image recognition, natural language processing, and predictive modeling.
Def: Supervised learning is where the computer is given a set of training data, and it learns how to predict outcomes based on that data. Labeled data indicates that the input data has already been tagged with the appropriate output.
Def: Basically, it is the task of learning a function that maps the input set and returns an output. In supervised methods, we have a target variable. This means that the algorithm is fed with examples containing several features and one outcome variable. The outcome variable can be binary or multifactorial[2].
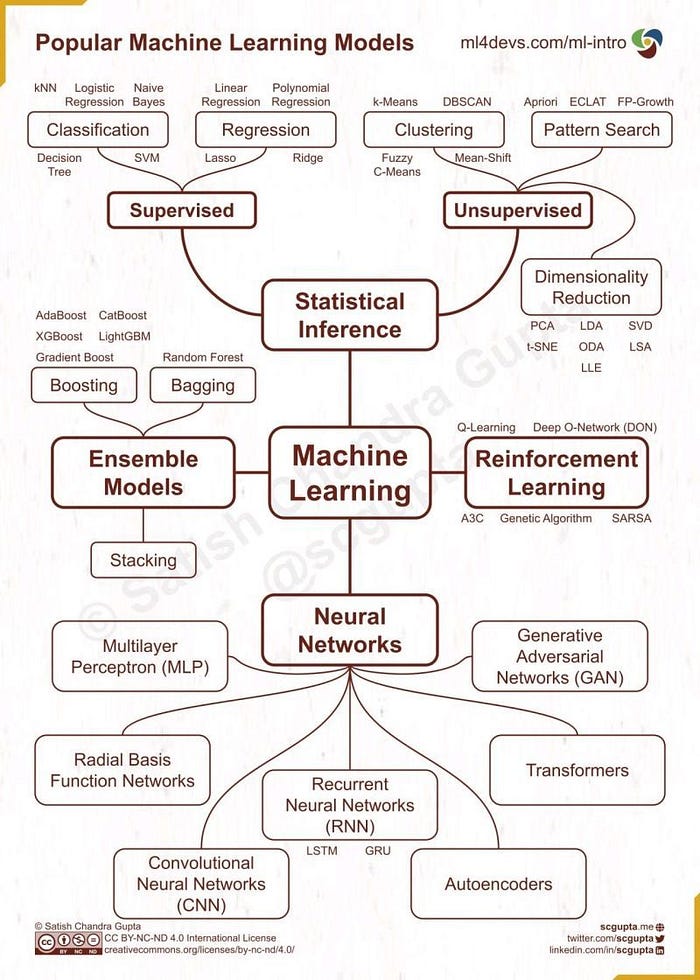
Def: Supervised learning algorithms make predictions based on a set of examples. For example, historical sales can be used to estimate future prices. With supervised learning, you have an input variable that consists of labeled training data and a desired output variable. You use an algorithm to analyze the training data to learn the function that maps the input to the output. This inferred function maps new, unknown examples by generalizing from the training data to anticipate results in unseen situations. Some of its examples are: Linear Regression, Logistic Regression, KNN, etc.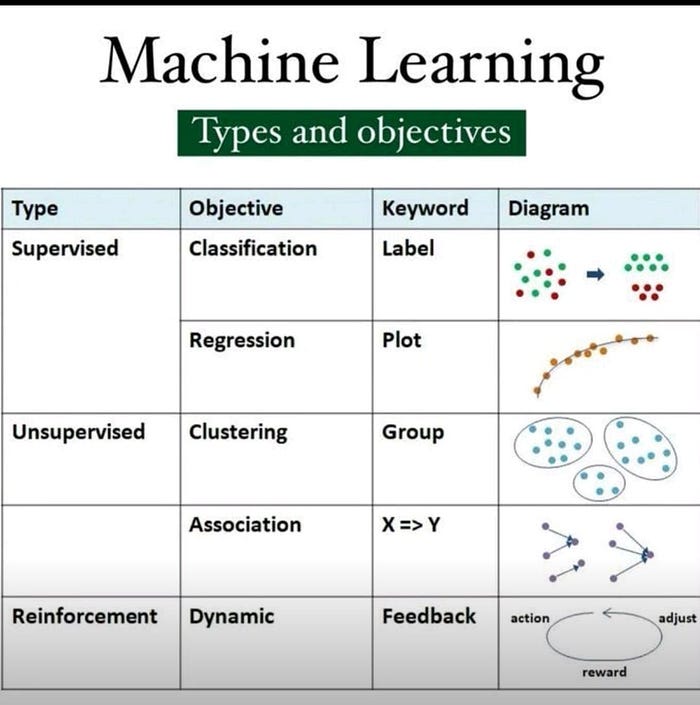
1.2- Attributes and Features
In a labeled data set, the attributes represent the names of the data’s characteristics, such as clump thickness, uniformity of cell size, uniformity of cell shape, and marginal adhesion. The columns, on the other hand, are referred to as features, which include the actual data points. Each observation or data point on a plot represents a single row on the chart
1.3- Numerical and Categorical Data
The data in supervised learning can be either numerical or categorical. Numerical data consists of numeric values, while categorical data contains characters instead of numbers. In the case of classification tasks, the data set is typically categorical, as it is focused on predicting discrete class labels or categories. On the other hand, regression tasks involve predicting continuous values
1.4- Example
Imagine you are teaching a kid to differentiate dogs from cats: at first, you show him many images of both animals, identifying each of them. With these examples, he can associate each animal with its name and then classify new images correctly [4]. Supervised learning has exactly the same idea: from a big train dataset, the algorithm “learns” the relationship between data and label and, therefore, it can predict the result of any other input [4].
1.5- Mathematics
In mathematical terms, we are trying to find an expression Y = f(X) + b that can predict the results. Where X is the input, Y is the prediction, and f(X) + b is the model learned by the algorithm [4]. Imagine you are teaching a kid to differentiate dogs from cats: at first, you show him many images of both animals, identifying each of them. With these examples, he can associate each animal with its name and then classify new images correctly. Supervised learning has exactly the same idea: from a big train dataset, the algorithm “learns” the relationship between data and label and, therefore, it can predict the result of any other input. In mathematical terms, we are trying to find an expression Y = f(X) + b that can predict the results. Where X is the input, Y is the prediction, and f(X) + b is the model learned by the algorithm.
In mathematical terms, we are trying to find an expression Y = f(X) + b that can predict the results. Where X is the input, Y is the prediction, and f(X) + b is the model learned by the algorithm.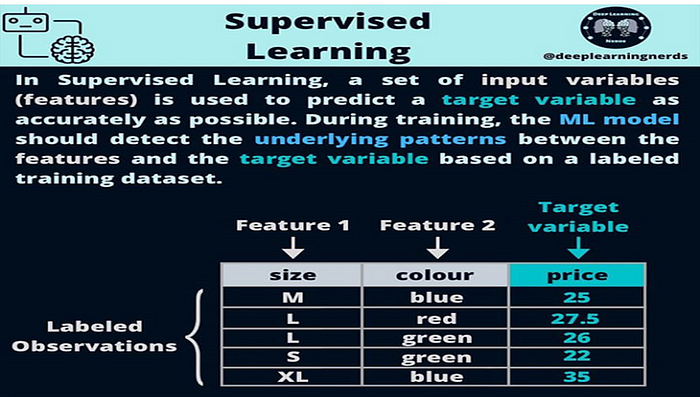
1.6- Example 2
Given this data, let’s say you have a friend who owns a house that is, say 750 square feet, and hoping to sell the house and they want to know how much they can get for the house. So how can the learning algorithm help you?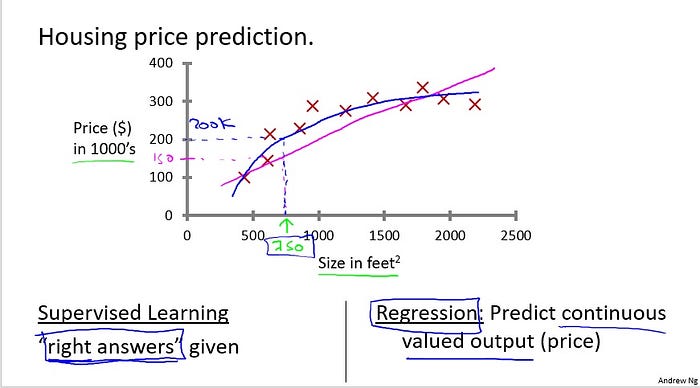 One thing a learning algorithm might be able to do is put a straight line through the data or to fit a straight line to the data and, based on that, it looks like maybe the house can be sold for maybe about $150,000.
One thing a learning algorithm might be able to do is put a straight line through the data or to fit a straight line to the data and, based on that, it looks like maybe the house can be sold for maybe about $150,000.
But maybe this isn’t the only learning algorithm you can use. There might be a better one. For example, instead of sending a straight line to the data, we might decide that it’s better to fit a quadratic function or a second-order polynomial to this data. And if you do that, and make a prediction here, then it looks like, well, maybe we can sell the house for closer to $200,000.
One of the things we’ll talk about later is how to choose and how to decide do you want to fit a straight line to the data or do you want to fit the quadratic function to the data and there’s no fair picking whichever one gives your friend the better house to sell. But each of these would be a fine example of a learning algorithm.
So this is an example of a supervised learning algorithm. And the term supervised learning refers to the fact that we gave the algorithm a data set in which the “right answers” were given. That is, we gave it a data set of houses in which for every example in this data set, we told it what is the right price so what is the actual price that, that house sold for and the toss of the algorithm was to just produce more of these right answers such as for this new house, you know, that your friend may be trying to sell.
Section 2- Type of Supervised Learning
The two main tasks supervised learning aims to solve are classification, regression. The three main tasks supervised learning aims to solve are: classification, regression and forcasting.The former, as the name says, is related to assign a label to the data, such as classify images in dog, cat or bird. The latter aims to predict a continuous value given some conditions, for example, estimate a house price given its size, location and number of rooms [4].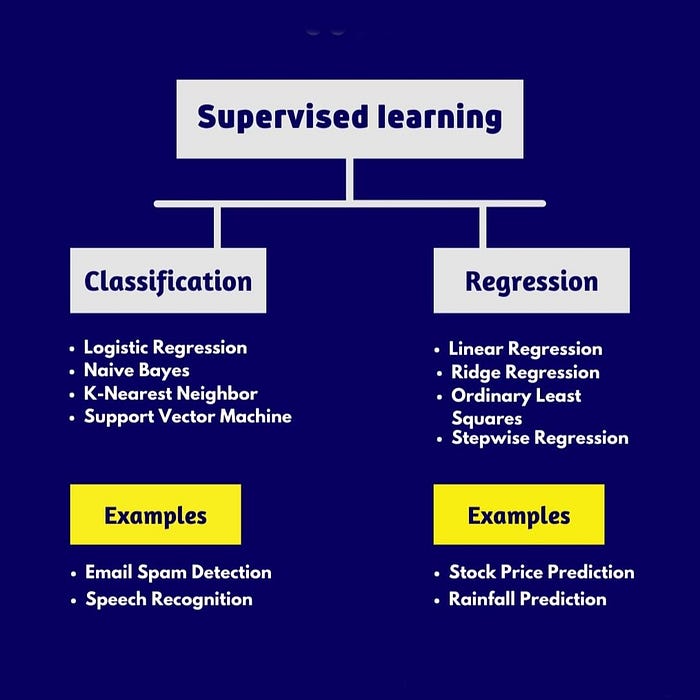
2.1- Regression Problem
Def: Regression, on the other hand, involves predicting continuous values. Using the same CO2 emissions data set, we can use regression to predict the CO2 emission of a new car by considering other fields such as engine size or number of cylinders.
When predicting continuous values, the problems become a regression problem.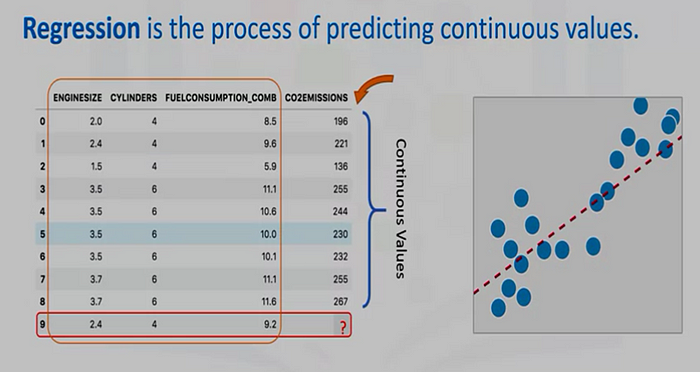 To define with a bit more terminology this is also called a regression problem and by regression problem I mean we’re trying to predict a continuous value output. Namely the price. So technically I guess prices can be rounded off to the nearest cent. So maybe prices are actually discrete values, but usually we think of the price of a house as a real number, as a scalar value, as a continuous value number and the term regression refers to the fact that we’re trying to predict the sort of continuous values attribute.
To define with a bit more terminology this is also called a regression problem and by regression problem I mean we’re trying to predict a continuous value output. Namely the price. So technically I guess prices can be rounded off to the nearest cent. So maybe prices are actually discrete values, but usually we think of the price of a house as a real number, as a scalar value, as a continuous value number and the term regression refers to the fact that we’re trying to predict the sort of continuous values attribute.
2.2-Classificaiton Problem
Def: Classification is the process of predicting discrete class labels or categories. For example, using a data set related to CO2 emissions of different cars, we can classify a new car’s emissions based on its engine size or number of cylinders
Here’s another supervised learning example, some friends and I were actually working on this earlier. Let’s see you want to look at medical records and try to predict of a breast cancer as malignant or benign. If someone discovers a breast tumor, a lump in their breast,
When the data are being used to predict a categorical variable, supervised learning is also called classification. This is the case when assigning a label or indicator, either dog or cat to an image. When there are only two labels, this is called binary classification. When there are more than two categories, the problems are called multi-class classification.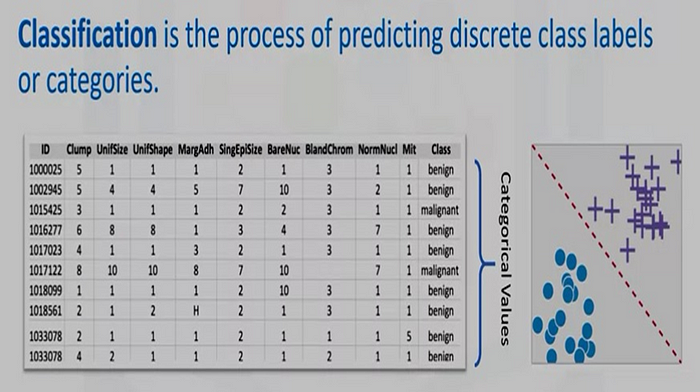 a malignant tumor is a tumor that is harmful and dangerous and a benign tumor is a tumor that is harmless.
a malignant tumor is a tumor that is harmful and dangerous and a benign tumor is a tumor that is harmless.
So obviously people care a lot about this. Let’s see a collected data set and suppose in your data set you have on your horizontal axis the size of the tumor and on the vertical axis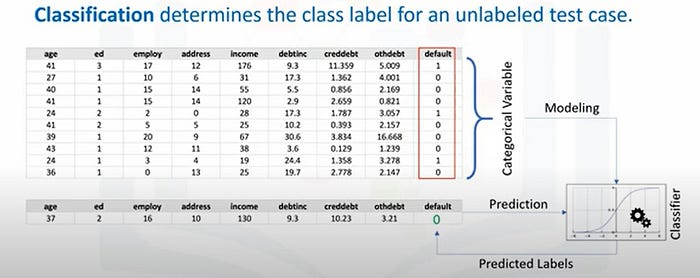 I’m going to plot one or zero, yes or no, whether or not these are examples of tumors we’ve seen before are malignant which is one or zero if not malignant or benign. So let’s say our data set looks like this where we saw a tumor of this size that turned out to be benign. One of this size, one of this size. And so on. And sadly we also saw a few malignant tumors, one of that size, one of that size, one of that size… So on. So this example… I have five examples of benign tumors shown down here, and five examples of malignant tumors shown with a vertical axis value of one.
I’m going to plot one or zero, yes or no, whether or not these are examples of tumors we’ve seen before are malignant which is one or zero if not malignant or benign. So let’s say our data set looks like this where we saw a tumor of this size that turned out to be benign. One of this size, one of this size. And so on. And sadly we also saw a few malignant tumors, one of that size, one of that size, one of that size… So on. So this example… I have five examples of benign tumors shown down here, and five examples of malignant tumors shown with a vertical axis value of one.
And let’s say we have a friend who tragically has a breast tumor, and let’s say her breast tumor size is maybe somewhere around this value. The machine learning question is, can you estimate what is the probability, what is the chance that a tumor is malignant versus benign?
To introduce a bit more terminology this is an example of a classification problem. The term classification refers to the fact that here we’re trying to predict a discrete value output: zero or one, malignant or benign.
And it turns out that in classification problems sometimes you can have more than two values for the two possible values for the output. As a concrete example maybe there are three types of breast cancers and so you may try to predict the discrete value of zero, one, two, or three with zero being benign. Benign tumor, so no cancer. And one may mean, type one cancer, like, you have three types of cancer, whatever type one means. And two may mean a second type of cancer, a three may mean a third type of cancer. But this would also be a classification problem, because this other discrete value set of output corresponding to, you know, no cancer, or cancer type
one, or cancer type two, or cancer type three.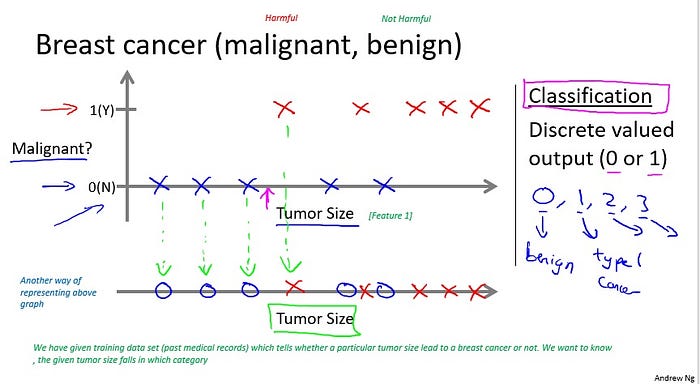 In classification problems there is another way to plot this data. Let me show you what I mean. Let me use a slightly different set of symbols to plot this data. So if tumor size is going to be the attribute that I’m going to use to predict malignancy or benignness, I can also draw my data like this. I’m going to use different symbols to denote my benign and malignant, or my negative and positive examples.
In classification problems there is another way to plot this data. Let me show you what I mean. Let me use a slightly different set of symbols to plot this data. So if tumor size is going to be the attribute that I’m going to use to predict malignancy or benignness, I can also draw my data like this. I’m going to use different symbols to denote my benign and malignant, or my negative and positive examples.
So instead of drawing crosses, I’m now going to draw O’s for the benign tumors. Like so. And I’m going to keep using X’s to denote my malignant tumors.
Okay? I hope this is beginning to make sense. All I did was I took, you know, these, my data set on top and I just mapped it down. To this real line like so. And started to use different symbols, circles, and crosses, to denote malignant versus benign examples.
Now, in this example, we use only one feature or one attribute, mainly, the tumor size in order to predict whether the tumor is malignant or benign. In other machine learning problems when we have more than one feature, more than one attribute.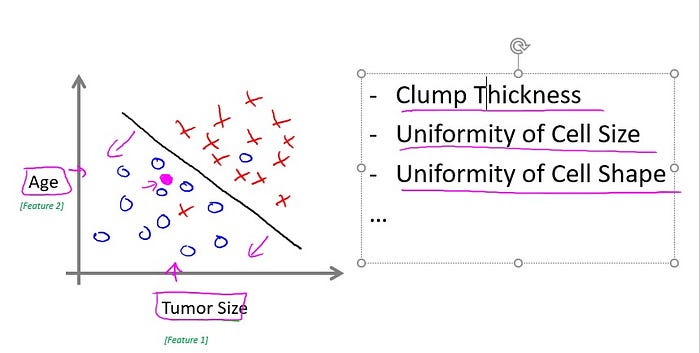 Here’s an example. Let’s say that instead of just knowing the tumor size, we know both the age of the patients and the tumor size. In that case maybe your data set will look like this where I may have a set of patients with those ages and that tumor size and they look like this. And a different set of patients, they look a little different, whose tumors turn out to be malignant, as denoted by the crosses.
Here’s an example. Let’s say that instead of just knowing the tumor size, we know both the age of the patients and the tumor size. In that case maybe your data set will look like this where I may have a set of patients with those ages and that tumor size and they look like this. And a different set of patients, they look a little different, whose tumors turn out to be malignant, as denoted by the crosses.
So, let’s say you have a friend who tragically has a tumor. And maybe, their tumor size and age falls around there. So given a data set like this, what the learning algorithm might do is throw the straight line through the data to try to separate out the malignant tumors from the benign ones and, so the learning algorithm may decide to throw the straight line like that to separate out the two classes of tumors. And. You know, with this, hopefully you can decide that your friend’s tumor is
more likely to if it’s over there, that hopefully your learning algorithm will say that your friend’s tumor falls on this benign side and is therefore more likely to be benign than malignant.
In this example we had two features, namely, the age of the patient and the size of the tumor. In other machine learning problems we will often have more features, and my friends that work on this problem, they actually use other features like these, which is clump thickness, the clump thickness of the breast tumor. Uniformity of cell size of the tumor. Uniformity of cell shape of the tumor, and so on, and other features as well. And it turns out one of the interes-, most interesting learning algorithms that we’ll see in this class is a learning algorithm that can deal with, not just two or three or five features, but an infinite number of features. On this slide, I’ve
listed a total of five different features. Right, two on the axes and three more up here.
But it turns out that for some learning problems, what you really want is not to use, like, three or five features. But instead, you want to use an infinite number of features, an infinite number of attributes, so that your learning algorithm has lots of attributes or features or cues with which to make those predictions. So how do you deal with an infinite number of features? How do you even store an infinite number of things on the computer when your computer is gonna run out of memory. It turns out that when we talk about an algorithm called the Support Vector Machine, there will be a neat mathematical trick that will allow a computer to deal with an infinite number of features. Imagine that I didn’t just write down two features here and three features on the right. But, imagine that I wrote down an infinitely long list, I just kept writing more and more and more features. Like an infinitely long list of features. Turns out, we’ll be able to come up with an algorithm that can deal with that.
So, just to recap. In this class we’ll talk about supervised learning. And the idea is that, in supervised learning, in every example in our data set, we are told what is the “correct answer” that we would have quite liked the algorithms have predicted on that example. Such as the price of the house, or whether a tumor is malignant or benign. We also talked about the regression problem. And by regression, that means that our goal is to predict a continuous-valued output. And we talked about the classification problem, where the goal is to predict a discrete value output.
2. 3- Forecasting:
This is the process of making predictions about the future based on past and present data. It is most commonly used to analyze trends. A common example might be an estimation of the next year sales based on the sales of the current year and previous years.
Section 3- Semi-supervised learning
The challenge with supervised learning is that labeling data can be expensive and time-consuming. If labels are limited, you can use unlabeled examples to enhance supervised learning. Because the machine is not fully supervised in this case, we say the machine is semi-supervised. With semi-supervised learning, you use unlabeled examples with a small amount of labeled data to improve the learning accuracy.
Section 4- Unsupervised Learning
Unlike supervised learning, unsupervised learning does not involve guiding or supervising a model. Instead, the model works on its own to discover patterns and information that may not be visible to the human eye. Unsupervised learning algorithms train on unlabeled data, making it more challenging compared to supervised learning.
Def1. Unsupervised learning involves training a model using unlabeled data.
Def 2:The objective is for the model to find patterns or relationships within the data.
Def 3: Unsupervised learning is where the computer is given data but not told what to do with it; it has to figure out how to group or cluster the data itself. With this method, we have no outcome variable or label variable. This way, the algorithm search for patterns in all data and all variables.
Def 4: Unsupervised learning is another type of machine learning in which the computer is trained on unlabeled data, meaning the data does not have any pre-existing labels or targets. The goal of unsupervised learning is to find hidden patterns or structures in the data without the guidance of a labeled dataset [6].Def:When performing unsupervised learning, the machine is presented with totally unlabeled data. It is asked to discover the intrinsic patterns that underlie the data, such as a clustering structure, a low-dimensional manifold, or a sparse tree and graph.
4.1- Background:
4.2- Commonly used Methos
Some commonly used methods include clustering and association. Unsupervised methods are particularly useful when the researcher does not know much about the data and wants to find patterns or associations among observations.[5]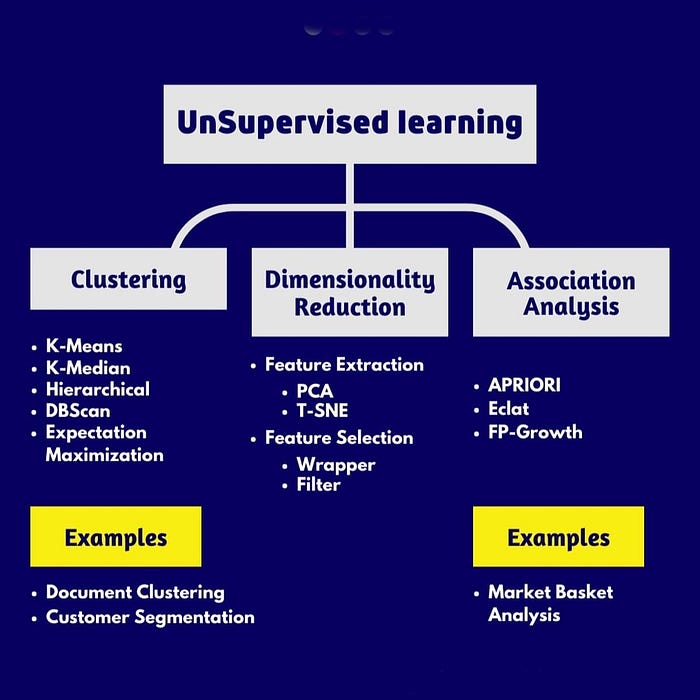
4.3- How does Unsupervised Learning work?
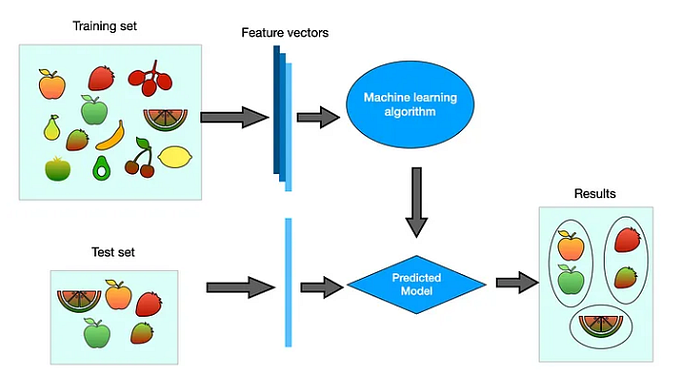
4.4- Application
Dimension Reduction and Feature Selection
Unsupervised learning techniques focus on tasks such as dimension reduction, density estimation, market basket analysis, and clustering. Dimensionality reduction and feature selection play a crucial role in unsupervised learning by reducing redundant features and making classification easier. This helps in discovering hidden patterns and relationships within the data.
Market Basket Analysis
Market basket analysis is a modeling technique that explores the theory that if a certain group of items is bought, there is a likelihood of buying another group of items. It helps in identifying associations and relationships between different items in a dataset.
Density Estimation
Density estimation is a concept used to explore data and find structure within it. It is a simple yet effective technique to analyze the distribution of data points and identify patterns or clusters.
Clustering
Clustering is one of the most popular unsupervised machine learning techniques. It involves grouping data points or objects that are similar in some way. Cluster analysis has various applications, such as customer segmentation based on certain characteristics or organizing and grouping favorite types of music. Clustering helps in discovering structure, summarization, and anomaly detection within the data.
Section 5- Reinforcement Learning
What is Reinforcement learning? Def 1: Reinforcement learning involves training a model by rewarding correct behavior and punishing incorrect behavior. This type of machine learning is often used in gaming simulations.Reinforcement learning (RL) is a type of machine learning where an agent learns to behave in an environment by trial and error. The agent receives rewards for taking actions that lead to desired outcomes, and penalties for taking actions that lead to undesired outcomes. Over time, the agent learns to take actions that maximize its rewards. Def 2:Reinforcement Learning (RL) is a type of machine learning algorithm that allows an agent to learn through trial and error by interacting with an environment. The agent receives feedback in the form of rewards or penalties for the actions it takes in the environment. The goal of the agent is to learn a policy that maximizes the total reward it receives over time [6].
Reinforcement learning is another branch of machine learning which is mainly utilized for sequential decision-making problems. In this type of machine learning, unlike supervised and unsupervised learning, we do not need to have any data in advance; instead, the learning agent interacts with an environment and learns the optimal policy on the fly based on the feedback it receives from that environment.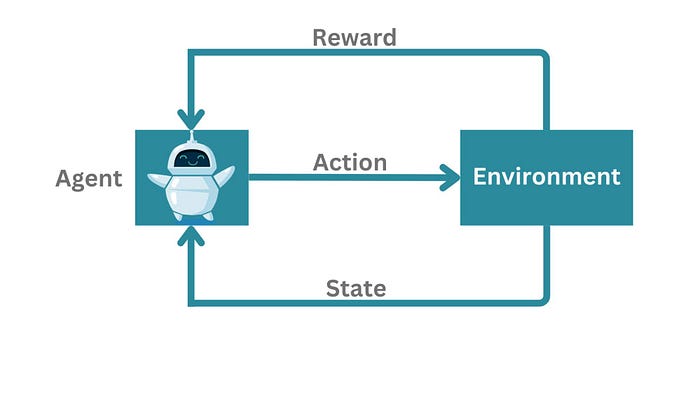
 RL is a powerful tool that can be used to solve a wide variety of problems, including game playing, robotics, and finance. Some of the most successful RL algorithms include Q-learning, SARSA, and Deep Q-Networks.
RL is a powerful tool that can be used to solve a wide variety of problems, including game playing, robotics, and finance. Some of the most successful RL algorithms include Q-learning, SARSA, and Deep Q-Networks.
Example
Here is an example of how RL can be used to solve a problem. Let’s say we want to train a robot to walk. We can create an environment for the robot that consists of a treadmill and a reward function that gives the robot a reward for taking steps in the forward direction. The robot can then use RL to learn how to walk by trial and error.At first, the robot will probably stumble and fall. However, over time, it will learn to take actions that lead to rewards, such as taking steps in the forward direction. Eventually, the robot will learn to walk without falling.
Commonly used Methos
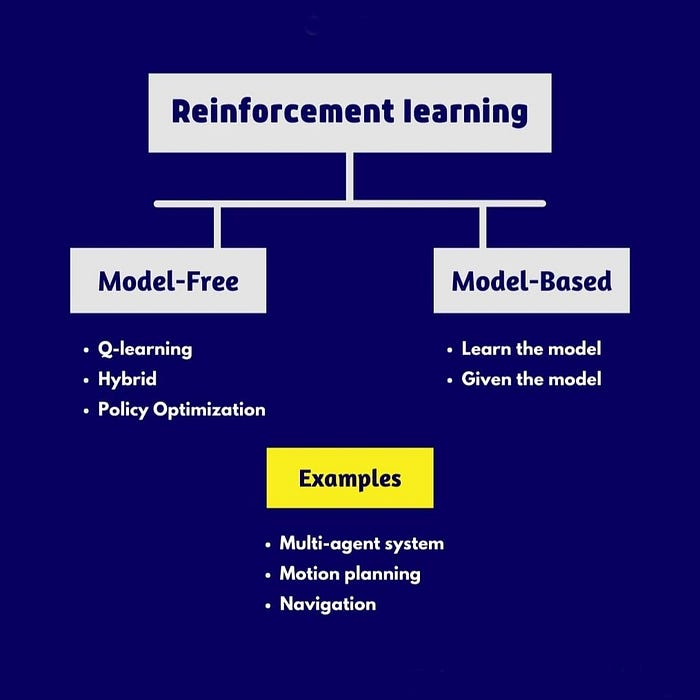
Reinforcement learning algorithms can be broadly categorized into two types [6]:
Model-based algorithms: These algorithms explicitly learn a model of the environment, including transition probabilities and rewards. They use this learned model to plan and make decisions. Examples include Monte Carlo methods, Temporal Difference (TD) learning, and Q-learning.
Model-free algorithms: These algorithms directly learn the optimal policy or value function without building an explicit model of the environment. They rely on trial-and-error learning through repeated interactions. Examples include Q-learning, SARSA, Deep Q-Networks (DQN), and Proximal Policy Optimization (PPO).
Section 6- Comparison
The biggest difference between supervised and unsupervised learning is the presence or absence of labeled data. Supervised learning deals with labeled data, which enables the use of machine learning algorithms for classification and regression. On the other hand, unsupervised learning deals with unlabeled data, where techniques like clustering are used to discover patterns and relationships.
6.1- Models and Evaluation
Supervised learning has a wider range of models and evaluation methods compared to unsupervised learning. In supervised learning, evaluation methods can be used to ensure the accuracy of the model’s outcome. However, in unsupervised learning, the lack of labeled data makes it challenging to evaluate the model’s accuracy
6.2- Control and Environment
Supervised learning provides a more controllable environment as the model’s outcome is guided by the labeled data. On the other hand, unsupervised learning creates a less controllable environment as the model works independently to discover patterns and relationships.
Conclusion
In conclusion, supervised learning involves teaching a machine learning model using labeled data, while unsupervised learning focuses on discovering patterns and relationships in unlabeled data. Supervised learning techniques like classification and regression are used for predicting class labels and continuous values, respectively. Unsupervised learning techniques like clustering, dimension reduction, density estimation, and market basket analysis help identify hidden patterns and relationships. While supervised learning has more models and evaluation methods, unsupervised learning provides a more exploratory approach to data analysis. Both types of learning have their own applications and play a crucial role in machine learning and data analysis. Thank you for reading!
Please Follow and 👏 Clap for the story courses teach to see latest updates on this story
If you want to learn more about these topics: Python, Machine Learning Data Science, Statistic For Machine learning, Linear Algebra for Machine learning Computer Vision and Research
Then Login and Enroll in Coursesteach to get fantastic content in the data field.
Stay tuned for our upcoming articles because we research end to end , where we will explore specific topics related to Machine Learning in more detail!
Remember, learning is a continuous process. So keep learning and keep creating and Sharing with others!💻✌️
Note:if you are a Machine Learning export and have some good suggestions to improve this blog to share, you write comments and contribute.
if you need more update about Machine Learning and want to contribute then following and enroll in following
👉Course: Machine Learning (ML)
👉📚GitHub Repository
👉 📝Notebook
Do you want to get into data science and AI and need help figuring out how? I can offer you research supervision and long-term career mentoring.
Skype: themushtaq48, email:mushtaqmsit@gmail.com
Contribution: We would love your help in making coursesteach community even better! If you want to contribute in some courses , or if you have any suggestions for improvement in any coursesteach content, feel free to contact and follow.
Together, let’s make this the best AI learning Community! 🚀
👉WhatsApp
👉 Facebook
👉Github
👉LinkedIn
👉Youtube
👉Twitter
Source
1- Main concepts behind Machine Learning
2- 7 Important Concepts in Artificial Intelligence and Machine Learning
3-Elucidating the Power of Inferential Statistics To Make Smarter Decisions! (Unread)
4-Main concepts behind Machine Learning
5-Important Concepts in Artificial Intelligence and Machine Learning
6-Machine Learning: An Introductory Tutorial for Beginners
7- Machine learning(Andrew)
9- Machine learning with Python (IBM)
10–Which machine learning algorithm should I use?










![[LIVE] Engage2Earn: auspol follower rush](https://cdn.bulbapp.io/frontend/images/c1a761de-5ce9-4e9b-b5b3-dc009e60bfa8/1)



















































