Data Science
What is Data #Science?
Data science is the process of obtaining information by using statistical, mathematical and computer science techniques to analyze, interpret and derive meaning from large amounts of data. It aims to produce solutions to data-oriented problems by combining data science, information technologies, statistics, mathematics and business understanding. This discipline helps organizations achieve competitive advantage, support their decisions and predict future trends, especially in the age of big data.
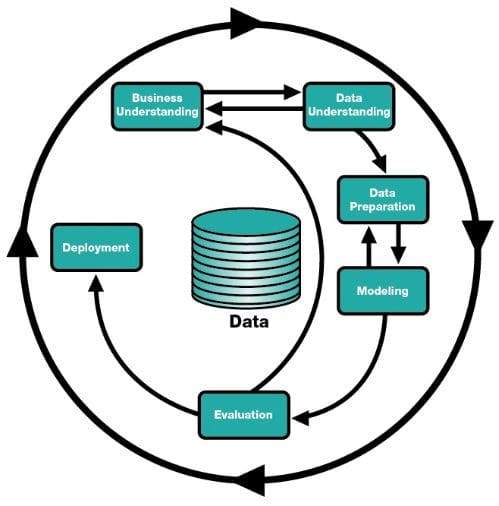
Data science is about a process that usually consists of a series of steps. These steps include: data collection, data cleaning and preprocessing, exploratory data analysis, modelling, evaluation and finally distribution. Each step is used to understand the data, extract features, select an algorithm suitable for the model, and communicate the results effectively.
History of Data Science
The origins of data science date back to ancient times, but the discipline's current form is linked to the rise of modern information technologies. The advent of early computers and programming languages increased the capacity to process large amounts of data, making data science possible.
In the 1950s, statisticians and mathematicians began using computers for data analysis. However, the popularization of the term “data science” and the formation of the formal discipline in this field is a more recent event. By the early 2000s, major technology companies and research institutions began developing proprietary techniques and algorithms to effectively analyze large amounts of data.
Today, data science plays an important role in many industries. Across industries such as finance, healthcare, retail, education and more, organizations are using data science applications to support their decisions, optimize their operations and discover new opportunities. Data science is a constantly evolving and changing field and will become even more important with future technological developments.
#Data Science Process
Each stages of the data science process:
1. Data Collection:
The starting point of the data science process is to collect the data to be used for analysis. In this process, in addition to the internal data owned by organizations, data obtained from external sources can also be used. The data collection process includes steps such as identifying data sources, selecting data collection methods, and creating an appropriate infrastructure to store the data. Obtaining quality and diverse data during the data collection phase is critical to a successful data science project.
2. Data Cleaning and Preprocessing:
The data collected may often be incomplete, inaccurate or inconsistent. Therefore, the data cleaning and preprocessing phase is a critical part of preparing the data for analysis. At this stage, operations such as editing the data, correcting missing or incorrect values, and standardizing data formats are performed. Additionally, it is aimed to clean unnecessary or duplicate data and bring the data into a suitable format for analysis.
3. Exploratory Data Analysis (EDA):
Exploratory Data Analysis (EDA) is a phase used to understand the data set and discover patterns within it. This phase involves examining the dataset using tools such as statistical graphs, visualizations, and basic statistics. EDA is used to understand trends, outliers, distributions, and relationships in the data set. This phase helps data scientists identify important features and potential problems within the data set.
4. Modeling:
In the modeling phase, data scientists select an appropriate machine learning or statistical model to achieve the set goals. These models aim to predict or classify future events using previously discovered patterns. The modeling process includes the steps of creating the model on training data, evaluating the model on test data, and improving the performance of the model. The algorithms used in the modeling phase may vary depending on the problem type and the characteristics of the data set.
5. Evaluation:
Once the model is created, it is important to evaluate its performance. At this stage, the success of the model is analyzed using performance criteria such as model accuracy, precision, and recall. Test data is used to understand how the model performs on real-world data. Areas where the model fails are identified and the model is updated if necessary.
6. Distribution:
A successfully evaluated model is made ready for use and integrated into business processes. Making the model available and deploying it often involves software development processes. During the deployment phase, infrastructures are created so that the model can interact with real-time data and be constantly updated. Making the model available in an interactive way helps maximize the business value of data science projects.
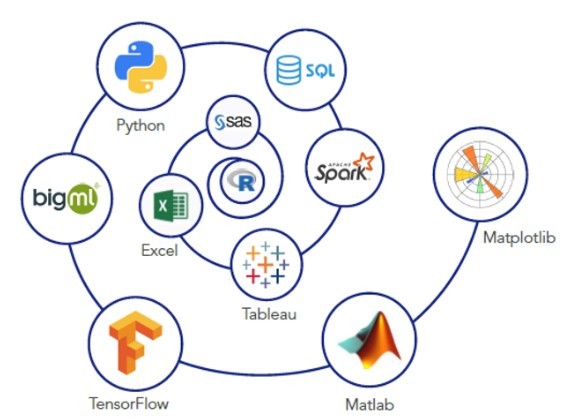
Data Science Tools and Technologies
1. Programming Languages (Python, R):
#Python:
Python is a general-purpose programming language and is widely used in the field of data science. One of the main reasons why Python is preferred in this field is that it is easy to learn and supported by a large community. The Pandas library available in Python enables efficient manipulation of data frames and time series. Libraries such as Matplotlib and Seaborn are used to visualize data, while NumPy optimizes mathematical operations.
#R:
R is a programming language designed specifically for statistical analysis and data visualization. Widely used among data scientists and statisticians, R facilitates statistical analysis and visualization thanks to its special packages and functions. The Tidyverse suite includes a set of tools that include data manipulation, visualization and modeling processes.
2. Databases (SQL):
SQL is a structured query language and is used to access and manage databases. Data extraction, filtering and merging operations can be performed with SQL queries on relational databases (MySQL, PostgreSQL, SQLite) and big data platforms (Hadoop, Spark). In this way, data scientists can effectively use and analyze the data sets stored in their projects.
3. Statistical Tools:
Statistical tools play an important role in data science projects. Tools such as SPSS, SAS and STATA enable complex statistical analysis to be performed. These tools are often used to perform comprehensive statistical analyses, especially in the social sciences and healthcare.
4. #Machine Learning Libraries (TensorFlow, scikit-learn):
TensorFlow:
TensorFlow is an open source machine learning library used specifically for building and training deep learning models. It is possible to monitor model performance with tools such as TensorBoard. TensorFlow is backed by a large community and documentation, helping data scientists develop complex AI applications.
Scikit-learn:
scikit-learn is a Python-based machine learning library and supports basic machine learning tasks such as classification, regression, clustering, dimensionality reduction, and model selection. Its user-friendly interface and extensive documentation resources make it easy for data scientists to implement various machine learning algorithms and evaluate model performance.
These tools have complementary features by being used at different stages of the data science process. Python and R are powerful programming languages for data manipulation and analysis. SQL is a basic tool for accessing and managing databases. Statistical tools are used to perform complex analyses, while machine learning libraries provide model building and prediction capabilities. Effective use of these tools allows data scientists to successfully complete their projects.