Deep Diving into how EVM(Ethereum Virtual Machine) works?
You’ve probably heard of the Ethereum Virtual Machine(EVM) but you like me find it more than slightly intimidating. Below is my attempt to explain to you how EVM is and how it works:

- To start it’s important to understand what a virtual machine is. In the context of Ethereum, a virtual machine is a program built into the software(Ethereum clients) that recreates a computer’s functionality.
- To understand how it works, let’s take a look at its use through the lens of an Ethereum validator by breaking down some key categories: Clients, Storage, Transactions and Execution, Clients: To become a validator and produce blocks, running the EVM as a means to commute state transitions is necessary.
3. To best understand what state & state transitions are, consider that when you’re sending Ether, This requires a transition in the state of the blockchain.
Tokens now belong to a new account than before and this needs to be reflected in Ethereum’s map of who owns what. In order to do this, validators need to take inputs/transactions, run their respective instructions in the EVM, and print the output in a block header.
4.A validator runs the EVM by downloading an ETHEREUM client software that contains the EVM program. An Ethereum client contains the Ethereum Virtual Machine as well as other necessary features:
a) Memory Pool: Location of signed transactions ready to get included in a block gets stored.
b) JSON-RPC API: Provides a data structure for processing requests to read /write data to Ethereum.
6. There are many different types of clients that run in different languages, but they can interoperate with each other because they follow the same specifications in the Ethereum yellow paper.
7. Storage: How does the EVM store state prior to a new transaction? Like a computer, a virtual computer is able to store data. In the context of the EVM, one of its critical functions is to store the “state’ of all accounts and what information those accounts store.
8. The EVM stores state according to a data structure called a “Merkle Patricia trie”, which is able to contain all the key: value pairs of all addresses on Ethereum.
9. The keys correspond to both public and smart contract addresses, and their respective values represent the current state of those addresses
10. The value/state for each address is itself an encoding of the hash of the address’s respective code, a hash of the data stored by the account, tis balance, and the number of transactions it’s carried out.
11. A Merkle Patricia trie is used to store this data because it makes it easy to perform hashes of all the key-value pairs to eventually get to a singular “Merkle Root Hash” of the state of who owns what-a required field in the block header of a validator’s proposed block.
12. Because of how hashes work, even a minute change in blockchain state will result in a completely different root hash. The reason for mandating validators to include this root hash in a block header is that it significantly enhances the security of the network.
13. This is because it enables light nodes, which don’t have the space to store this Merkle Patricia trie, to verify the legitimacy of the block that a validator is attempting to proliferate.
14. A light node can compute a “Merkle Proof” with the root hash, account key, and balance value of the proposing full node, and compare that to a Merkle proof of its own address & balance. There would be no match in the Merkle proofs if there were any incorrect data
15. Transactions: When a user is submitting a signed transaction through a wallet, the transaction data is compiled into Bytecode and sent to a node using the aforementioned JSON-RPC API. Bytecode is the low-level language that the EVM reads to compute state transitions.
16. Bytecode appears as a HEX encoding of a string of binary. Collections of these bytes represent specific operations, known as opcodes that the EVM will perform.
17. Opcodes are instructions that the EVM follows to manipulate the input data/transaction on the stack (more on this later) as a means to change the state. HEX format is just a numeric system (like the binary and decimal system) that is used to convey binary in a readable way.
18. The reason why opcodes are important is that when computed, they enable the EVM to find the output of the state transition requested by the transaction
19. When sent to the mempool the bytecode is passed as an argument in a transaction broadcast to a node’s mempool using the JSON-RPC API. After this, the transaction sits in the mempool with other unconfirmed transactions ready to be included in a block by a validator
20. When a validator picks the transactions it wants to include in a block, it will have to compute state transitions as defined by the operations/opcodes indicated by each transaction’s respective bytecode. This is where the EVM’s core functionality — execution — comes in.
21. Execution: Storing the state of all accounts is data that the EVM stores permanently, but the EVM uses temporary memory to execute opcodes. To understand this, it’s necessary to understand two types of temporary memory — “stack” and “memory” used during opcode execution.
22. a) The stack is the data area where the computations as defined by opcodes are performed. b) Memory is an array of data that can be used to store information temporarily to pass through data required to compute the instructions on top of the stack.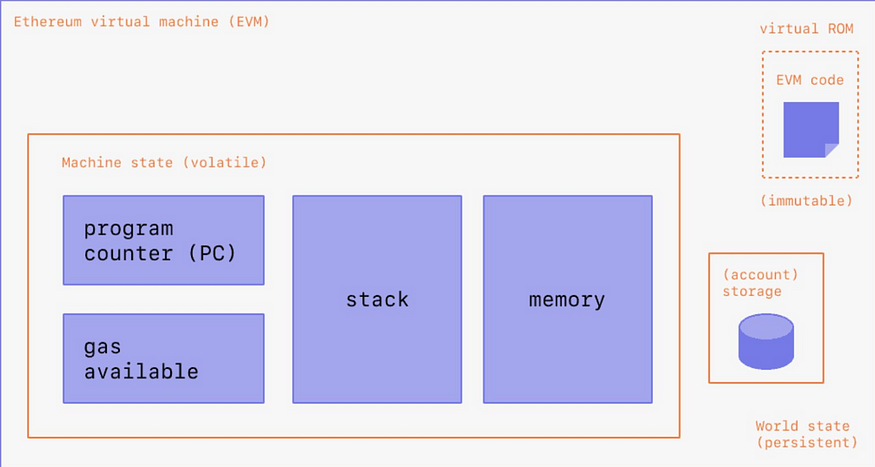
23. When transactions are accessed by the EVM through the mempool using the aforementioned client process, the EVM takes the instructions in the sequence specified by the bytecode and the bytecode gets separated into their respective opcodes.
24. The opcodes are sequentially loaded into the data area in a stacked sequence — where each opcode falls on top of another in the sequence specified by the bytecode.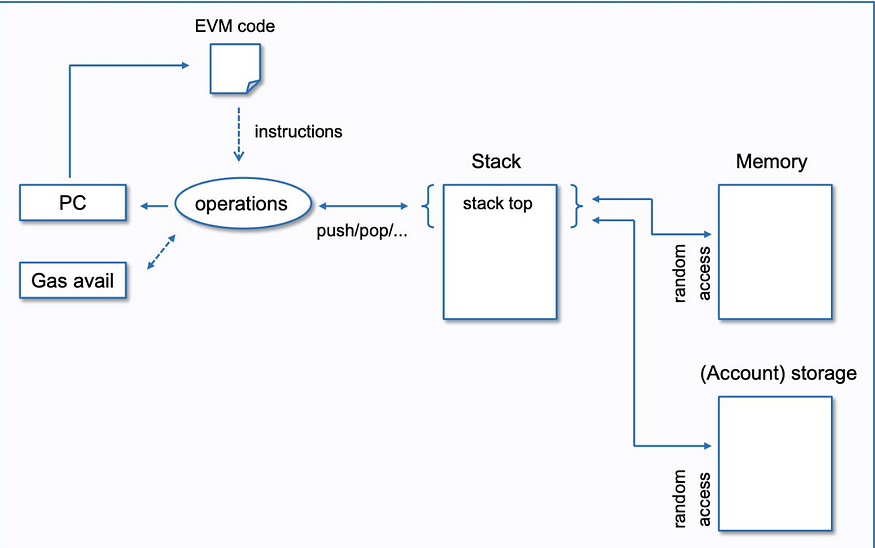
25. The stack follows the instructions at the top of the stack and utilizes data/variables moved to memory during the process to compute the instructions on top of the stack. The EVM also requires information about the state that it fetches from storage to run these opcodes too
26. When all opcodes have been run, this implies that any output about a change in state will be loaded to permanent storage by the stack. It’s important to note that each opcode results in a new computation of what the Ethereum state is, and each opcode has a specific cost.
27. Once each opcode is run, the amount of gas expended in executing it is subtracted from the available gas specified when the user originally submitted the transaction
28. If insufficient gas was sent to cover the cost of running the opcodes, the validator does not include the transaction in the block but the user doesn’t get refunded because the validator has already incurred the cost to run the computation.
29. Once this process has been completed for all transactions in the mempool the validator wants to include in the block, the validator can compute the aforementioned root hash of the new state and include it in the block header











![[ℕ𝕖𝕧𝕖𝕣] 𝕊𝕖𝕝𝕝 𝕐𝕠𝕦𝕣 𝔹𝕚𝕥𝕔𝕠𝕚𝕟 - And Now What.... Pray To The God Of Hopium?](https://cdn.bulbapp.io/frontend/images/79e7827b-c644-4853-b048-a9601a8a8da7/1)





![[LIVE] Engage2Earn: McEwen boost for Rob Mitchell](https://cdn.bulbapp.io/frontend/images/c798d46f-d3b8-4a66-bf48-7e1ef50b4338/1)













