Natural Language Processing(Part 2)-Tasks and Applications

Natural Language Processing Tasks and Applications
Description
In the vast realm of artificial intelligence, Natural Language Processing (NLP) stands out as a fascinating and dynamic field. NLP bridges the gap between computers and human language, enabling machines to understand, interpret, and generate human-like text. This transformative technology has far-reaching implications, influencing various industries and aspects of our daily lives. In this blog post, we will explore the key NLP tasks and their diverse applications, showcasing the extraordinary capabilities of language processing.
Natural Language Processing is a subfield of artificial intelligence that focuses on the interaction between computers and human language. The goal is to enable machines to comprehend, interpret, and generate text in a manner that mimics human language understanding. NLP involves a spectrum of tasks and applications, each designed to harness the power of language for different purposes.
we will explore the main NLP tasks and the most popular application for each task.Here are some key NLP tasks and their corresponding applications:
Sections
Text Classification
Information Extraction:
Machine Translation:
Question Answering
Text summarization
Language Generation:
Speech Recognition:
Conclusion
Section 1- Text Classification
Text Classification: assigning a category to a sentence or document (e.g. spam filtering) [1]. Text classification is the process of automatically categorizing text into predefined classes or categories. For example, a text classification algorithm might be used to classify emails as spam or not spam or to categorize news articles by topic[2]. There are three main types of classification:
- Binary: Two mutually exclusive categories (e.g., Spam detection)
- Multiclass: More than 2 mutually exclusive categories (e.g., Language detection)
- Multilabel: Non-mutually exclusive categories (e.g., movie genres)
Applications include:
- sentiment analysis,
- spam detection
- topic classification.
1.1- Sentiment Analysis
What is sentiment analysis
Def1: identifying the polarity of a piece of text [1]. Def 2: Sentiment analysis attempts to extract subjective qualities — attitudes, emotions, sarcasm, confusion, suspicion — from the text. Def 3: Determining the sentiment expressed in a piece of text (positive, negative, or neutral). Sentiment analysis is the process of determining the emotional tone behind a piece of text, such as a tweet, a product review, or customer feedback[2].
Applications
Sentiment analysis has numerous real-world applications, such as:
Sentiment analysis finds applications in social media monitoring, customer feedback analysis, and brand reputation management
Ways of using this form of text classification include sorting through customer reviews and inquiries and prioritizing negative ones, monitoring brand sentiment through social media responses, analyzing responses to surveys, or even determining gas in the competitor’s strategy using customers.
1- Customer Feedback Analysis
Companies can use sentiment analysis to analyze customer feedback from reviews, social media posts, or surveys. By understanding the sentiment behind these comments, businesses can gain valuable insights into customer satisfaction levels and make data-driven decisions to improve their products or services.
2- Brand Monitoring
Sentiment analysis can also be used for brand monitoring purposes. By analyzing social media mentions and online discussions related to a brand, companies can gauge public perception and take appropriate measures to manage their reputation.
Deep Learning and Machine Techniques
- For sentiment analysis, one popular architecture is the Long Short-Term Memory networks (LSTM), a type of Recurrent Neural Network (RNN) that can capture long-term dependencies in the text[4].
- Other architectures include Convolutional Neural Networks (CNNs), which can efficiently extract local features [4].
- More recently, Transformer-based models such as BERT, GPT, or RoBERTa, which are capable of capturing complex contextual relationships between words, have shown superior performance in this task [4].
1.2- Spam detection
Detecting spam alerts in emails and messages is one of the main applications that every big tech company tries to improve for its customers. Apple’s official messaging app and Google’s Gmail are great examples of such applications where spam detection works well to protect users from spam alerts.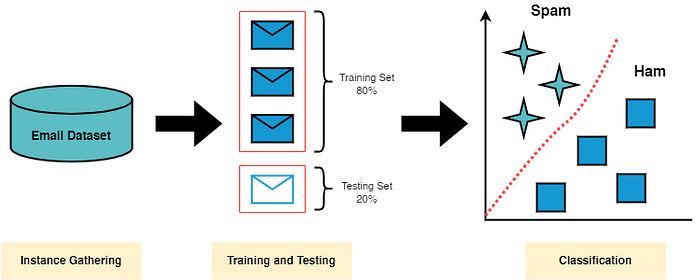
1.3- Topic classification
Topic classification is a supervised machine learning task that involves assigning a document to one of a predefined set of topics. The goal of topic classification is to identify the main topic of a document, such as “politics”, “sports”, or “technology”.
Topic classification is a challenging task because documents can often be about multiple topics, and the topics can be overlapping or ambiguous. Additionally, the language used to describe a topic can vary depending on the author and the context.
There are a number of different methods for topic classification, including:
- Naive Bayes: This is a simple but effective method that uses Bayes’ theorem to calculate the probability of a document belonging to a particular topic.
- Support vector machines: This is a more powerful method that uses a mathematical technique called support vector machines to classify documents.
- Neural networks: This is a more complex method that uses artificial neural networks to learn the relationships between words and topics.
1.4- Text classification models
NLP models for text classification are the various pre-trained models in use for natural language processing being done with artificial intelligence.In this section, we will be discussing two models that are highly in use globally.
XLNET:
XLNet is a language model that was developed by Google AI in 2020. It is a bidirectional transformer model that was trained on a massive dataset of text and code. XLNet is able to learn long-range dependencies between words, which makes it better at understanding and generating natural language. It doesn’t simply classify text but also takes the lead with more complex forms of processing natural language. The processes XLNET uses are based on two main ideas: generalized autoregressive pretraining and transformer-XL
BERT
BERT stands for Bidirectional Encoder Representations from Transformers. It is a language model that was developed by Google AI in 2018. BERT is a bidirectional model, which means that it can learn the relationships between words in a sentence in both directions, from left to right and from right to left. This makes BERT better at understanding the context of words, which is essential for tasks such as natural language inference and question answering.
BERT is the abbreviation for “bidirectional encoder representations from transformers” and is a neural network model, which means it uses RNNs (recurrent neural networks) as its main process for modeling languages, answering questions, and machine translation.
Section 2- Information Extraction:
What is information extraction: def 1: information extraction is extracting structured information from unstructured text sources like news articles or web pages. This includes tasks like named entity recognition, relation extraction, and event extraction. Def: Information extraction is the process of extracting structured data from unstructured text. For example, an information extraction algorithm might extract product information, such as price and availability, from an e-commerce website. Information extraction is used in a variety of industries, including e-commerce, finance, and healthcare, to extract structured data from unstructured text [2].
2.1- Sentence/document similarity
It determines how similar the two texts are.Sentence/document similarity is a measure of how similar two pieces of text are, or to what degree they express the same meaning. It is a common task in natural language processing (NLP) and has a wide range of applications, such as:
- Information retrieval: This involves searching for documents that are relevant to a particular query.
- Text summarization: This involves summarizing text into a shorter, more concise version.
- Paraphrase detection: This involves determining whether two sentences are paraphrases of each other.
- Question answering: This involves answering questions about text.
- Machine translation: This involves translating text from one language to another.
There are a number of different methods for measuring sentence/document similarity, including:
- Cosine similarity: This is a measure of the similarity between two vectors. In the context of sentence/document similarity, the vectors are typically the word embeddings of the sentences or documents.
- Jaccard similarity: This is a measure of the overlap between two sets. In the context of sentence/document similarity, the sets are typically the sets of words in the sentences or documents.
- Levenshtein distance: This is a measure of the edit distance between two strings. In the context of sentence/document similarity, the edit distance is the number of changes that need to be made to one string to make it the same as the other string.
Section 3- Question Answering
What is Question Answering means:
Def 1: Question Answering is the task of answering a question in natural language.Building systems that can answer questions posed by users based on a given context or knowledge base.
Def: Question answering is an NLP task where a system accurately answers a human-posed question. This task can range from answering simple factoid questions, like “Who is the president of the United States?” to more complex ones that require reasoning and understanding context, such as “What factors led to World War II?” [4],
The goal of a question answering system is to provide accurate, succinct, and relevant answers to user queries. The development of such systems involves a deep understanding of both natural language understanding and generation, making it a challenging but impactful task in the field of NLP.
Application:
1- Chatbots:
2- Virtual Assistant
Deep Learning and Machine Techniques
- Question answering tasks have seen great advancements with the introduction of Transformer architectures, especially BERT and its variants. These models are pre-trained on a large corpus of text and fine-tuned for the specific question answering task, making them powerful tools for understanding context and generating precise answers [4].
Section 4- Machine Translation
Def 1: it translates from one language to another. Def 2:Automatically translating text from one language to another. Machine translation is the process of automatically translating text from one language to another. For example, a machine translation algorithm might translate a news article from Spanish to English. Machine translation is used in a variety of industries, including e-commerce, international business, and government. Popular examples include Google Translate and Microsoft Translator.
Application
- Google Translate is an example of widely available NLP technology at work. Truly useful machine translation involves more than replacing words in one language with words of another.
Section 5- Text Summarization
What tis Text summarization means: def1: Generating concise summaries of longer texts while retaining important information. Text summarization is useful for news articles, research papers, and meeting transcripts. Creating a shortened version of several documents that preserves most of their meaning. Def:2: Text summarization uses NLP techniques to digest huge volumes of digital text and create summaries and synopses for indexes, research databases, or busy readers who don’t have time to read full text. Def: Text summarization is the process of automatically generating a condensed version of a longer piece of text. For example, a text summarization algorithm might take a long news article and generate a shorter summary of the main points. Text summarization is used in a variety of applications, including natural language processing, information retrieval, and machine learning [2].
Application
Deep Learning and Machine Techniques
- Text summarization is often approached with sequence-to-sequence models, such as those based on LSTM or GRU (Gated Recurrent Units) networks. These models read the input text as a sequence and generate the summary as another sequence [4].
- For abstractive summarization, Transformer-based models like T5 or BART have shown strong performance due to their capacity for understanding and generating complex text [4].
Section 6- Named Entity Recognition (NER)
Def: Named Entity means anything that is a real-world object such as a person, a place, any organization, any product which has a name. For example — “My name is Aman, and I and a Machine Learning Trainer”. In this sentence the name “Aman”, the field or subject “Machine Learning” and the profession “Trainer” are named entities.
Def: In Machine Learning Named Entity Recognition (NER) is a task of Natural Language Processing to identify the named entities in a certain piece of text.
Def: Named Entity Recognition (NER) is a technique used to extract entities such as people, organizations, and locations from unstructured text.
One way to perform NER is by using pre-trained models, such as the one provided by the spacy library in Python. Here's an example of how to use the spacy library to extract named entities from a piece of text.
How NER Work
The NER model works in a two-step process. The first step is to detect a named entity, and the second step is to categorize that entity. This is achieved by utilizing word vectors and creating a context window of these vectors. These vectors then feed into a neural network layer, followed by a logistic classifier, which identifies the specific entity type such as “location”. [4]
Real-life application:
- Have you ever used software known as Grammarly? It identifies all the incorrect spellings and punctuations in the text and corrects it. But it does not do anything with the named entities, as it is also using the same technique. In this article, I will take you through the task of Named Entity Recognition (NER) with Machine Learning.
Deep Learning and Machine Techniques
- For NER, Bidirectional LSTM (BiLSTM) along with a Conditional Random Field (CRF) layer is a commonly used architecture. The BiLSTM captures context from both directions for each token in the sentence, and the CRF helps to use the predictions of surrounding tokens to predict the current token’s class [4].
- More recently, Transformer-based models like BERT have shown high performance on NER tasks, given their ability to understand the context of each word in a sentence better [4].
Section 7- Language Generation or Text generation
what is Language Generation: Creating human-like text output based on given input or prompts. This includes tasks like. Def:Text generation is the process of automatically generating text, such as creating product descriptions or writing news articles. For example, a text generation algorithm might take a product image as input and generate a product description. Text generation is used in a variety of industries, including e-commerce, marketing, and content creation [2].
- chatbot responses
- dialogue systems,
- content generation for written narratives.
Section 8 - Speech Recognition:
What is speech recognition: Def1: Converting spoken language into written text. This technology is used in: Def: Speech recognition is the process of converting spoken words into written text. For example, a speech recognition algorithm might be used in a voice-controlled system, such as a virtual assistant, to transcribe spoken commands into text that can be understood by a computer. Speech recognition is used in a variety of industries, including healthcare, finance, and customer service [2].
- voice assistants
- transcription services,
- automated voice response systems.
Section 9- Text-to-Speech (TTS)
Text-to-speech (TTS) is a technology that converts written text into spoken words. It is commonly used in applications such as speech synthesis for the visually impaired, voice assistants, and automated customer service systems.
Real-life application
Some examples of TTS software include Google Text-to-Speech, Amazon Polly, and Apple’s Siri.
Section 10- Text Clustering
Text clustering is the process of grouping similar text documents together. For example, a text clustering algorithm might take a collection of news articles and group them into categories such as “sports”, “politics”, and “entertainment”. Text clustering is used in a variety of applications, including natural language processing, information retrieval, and machine learning [2].
Conclusion
In conclusion, Natural Language Processing is a multifaceted field with a plethora of tasks and applications that revolutionize the way we interact with technology. From enhancing communication to transforming industries, the power of language processing is reshaping our digital landscape and opening doors to unprecedented possibilities. As we journey into the future, the synergy between language and technology promises a world where machines truly understand and respond to the intricacies of human expression.
Please Follow and 👏 Clap for the story courses teach to see latest updates on this story
If you want to learn more about these topics: Python, Machine Learning Data Science, Statistic For Machine learning, Linear Algebra for Machine learning Computer Vision and Research
Then Login and Enroll in Coursesteach to get fantastic content in the data field.
Stay tuned for our upcoming articles where we will explore specific topics related to NLP in more detail!
Remember, learning is a continuous process. So keep learning and keep creating and sharing with others!💻✌️
Note:if you are a NLP export and have some good suggestions to improve this blog to share, you write comments and contribute.
if you need more update about NLP and want to contribute then following and enroll in following
👉Course: Natural Language Processing (NLP)
👉📚GitHub Repository
👉 📝Notebook
Do you want to get into data science and AI and need help figuring out how? I can offer you research supervision and long-term career mentoring.
Skype: themushtaq48, email:mushtaqmsit@gmail.com
Contribution: We would love your help in making coursesteach community even better! If you want to contribute in some courses , or if you have any suggestions for improvement in any coursesteach content, feel free to contact and follow.
Together, let’s make this the best AI learning Community! 🚀