We make PostgresSQL perform reads 2x faster then now?
TL;DR: Dealing with over 50 million records in a single table presents a significant challenge in managing data effectively.
Problem Assessment
The current company I’m working for manages tons of data. We rely on a range of storage options, using SQL Databases predominantly to capitalize on their potent features. Postgres which is hosted with AWS RDS — is a vital component of our infrastructure. Our system generates many analytical charts and executes joins for numerous rows in tables to serve thousands of users per day.
Managing data up to 10–20 million rows in one table was easy, but after 50🍋, you face new challenges. The biggest table whose performance was impacted was storing events. It was used basically in every report therefore we discovered the issue fast.
The table had 16 columns that were mostly varchar, jsonb or timestamp types. Only three of them would be important for this article — customer_id: varchar, created_at: timestamp and event_name: varchar
On average each query took about 2 minutes to complete. The worst case — 4 minutes.
Our queries usually were doing up to 5 joins to other tables, and on some custom reports up to 20. But all the main data were filtered using the events table created_at or event_name fields.
Solutions
At this point, we began to think about partitioning since It should help us logically separate data on the disk using partitions.
It means that Postgres would leverage those partitions later on to work only with a subset of data from the first touches rather than with a big single table.
There are two fundamental types of partitioning — manual with inherited tables and custom triggers and semi-automatic. Hopefully, we're using Postgres 14 which already supports a new semi-automatic type.
For partitioning, you need to choose a field and method of partitioning. There are three types of partitioning:
- By range
- By list
- By hash.
For our cases two of them suited perfectly: range and list: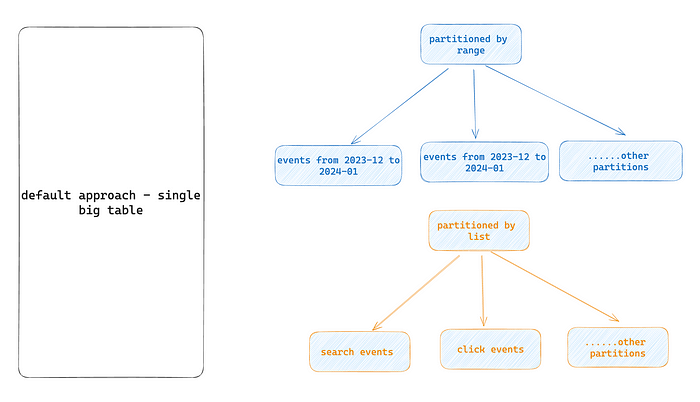 We wanted to migrate from a single big table and use one of those approaches either range partition by date or list partitioning by event type. Briefly how it would work in this case:
We wanted to migrate from a single big table and use one of those approaches either range partition by date or list partitioning by event type. Briefly how it would work in this case:
Range
For range partitioning by date(month), we need to create manually a main table and all of the tables that would hold data for one month. Suppose having 3 years of data -> 36 partitions. A lot of moving parts to manage😬
In case of range, partitioning Postgres would automatically check every query create_at condition and select the appropriate partition(s) for that exact date or range of dates. Therefore database would not even touch the other partitions and their indexes.
List
For event_name partition we would create only from 5 to 8 partitions since there were much fewer events than months and years 🙃 It means less SQL to manage. In this case, each event type is assigned to a partition so that it contains events of a specific type. Therefore during queries, postgres would automatically match event_name in the query and pull up the right partition(s) to select the data.
But it’s important to notice that for partitioning you better have evenly distributed data volumes. So that none of the partitions would get hot because of too many rows and too much operation with them.
We had a big imbalance for event_names volume — there were about 50% of one type of event in the whole dataset. During our tests for the list partitioned table, there were just a couple of cases when it performed better, but it didn’t drastically change the whole picture for most of the queries.
Date range partitoning!
Since from the beginning, the list partition didn’t show results — the decision was made to go for a more complex date range partitioning. Also, we discovered that the system generates 1–2 million events each month which should give us a pretty balanced distribution of data volume for each partition.
Great, so how to do that?
1. Creating a table with a partition key
CREATE TABLE events.events_partitioned_by_date
(
customer_id varchar(16) not null,
event_id varchar(36) not null,
created_at timestamp not null,
--other fields
constraint unique_customer_event
unique (customer_id, event_id, created_at)
) PARTITION BY RANGE (created_at);2. Creating default and other partitions for each month and year
CREATE TABLE IF NOT EXISTS events.default_events_partition PARTITION OF events.events_partitioned_by_date DEFAULT;
ALTER TABLE events.default_events_partition
ADD PRIMARY KEY (customer_id, event_id);
CREATE TABLE IF NOT EXISTS events.events_2020_01 PARTITION OF events.events FOR VALUES FROM ('2020-01-01') TO ('2020-02-01');
ALTER TABLE events.events_2020_01
ADD PRIMARY KEY (customer_id, event_id);
--- repeat command bellow changing partition dates and rangesAlso don’t forget to add indexes for your table after you created partitions!
3. Set up a recurring SQL code that would automatically create new partitions for one month ahead.
You can do it anywhere you want, either using cron plugins in Postgres or on scheduled AWS Lambda.
DO $$
BEGIN
IF NOT EXISTS (SELECT FROM pg_class WHERE relname = 'events_' || to_char(now() + interval '1 month', 'YYYY_MM'))
THEN
EXECUTE format(
'CREATE TABLE IF NOT EXISTS events.events_%s PARTITION OF events.events FOR VALUES FROM (''%s'') TO (''%s'');' ||
'ALTER TABLE events.events_%s ADD PRIMARY KEY (customer_id, event_id);',
to_char(now() + interval '1 month', 'YYYY_MM'),
to_char(date_trunc('month', now() + interval '1 month'), 'YYYY-MM-DD'),
to_char(date_trunc('month', now() + interval '2 months'), 'YYYY-MM-DD'),
to_char(now() + interval '1 month', 'YYYY_MM')
);
END IF;
END $$;4. Now you need to migrate data from your old big table to a new partitioned one.
This part was a bit painful since you can not move 50m rows in a snap of fingers especially when production is up and running.
That’s why I recommend writing a custom script that would iterate on each day and insert chunks of data into a new table sequentially. It took about 8h+ to complete migration with a custom script. Execution increased the database load by no more than 10–20% and everything was pretty smooth for customers.
Give me some 👏🏻 and comments so I know you want me to unveil and explain our migration Node.js script!
Update:
How to safely migrate millions of rows across Postgres Production tables?
5. Swap your table names to test a new approach
begin;
alter table events.events
rename to old_events;
alter table events.events_partitioned_by_date
rename TO events;
commit;That’s it, now let’s jump to the results.
Benchmarks
After all the things being done we tested our solution on one of our biggest customers. We measured the average execution time of all the queries before and after partitioning. Also, some selected queries were analyzed with a query planner to spot the exact difference.
Before partitioning:
- max: 4 minutes
- avg: 2 minutes
- min: 22 seconds
After partitioning:
- max: 2 minutes
- avg: 33 seconds
- min: 3s seconds
It was a great result for us since we had almost no timeout on the API side and made about 50% execution time improvement for the worst-case scenario.
All the queries started to perform better when we started shrinking the selected timeframe to less than 14 months. There were almost no differences for the whole time range selected. But the less data were filtered using created_at field the better it became to perform.
Thanks to partitions Postgres could eliminate big chunks of data from query selects and therefore perform far better with less data than a big single table.
Key Takeaways
Investigate your dataset wisely if you want to apply partitioning. Check whether all the other aspects are fine like data structure, indexes, or even your SQL provider setup. Try to make sure that all the basic improvements work first and only then move to partitions.
- Perform benchmarks for the worst performing queries with query analyzed and 3-D party tools like pgexplain.
- Document results and compare them side to side using production-ready queries to have real data.
- Try to make evenly distributed partitions to avoid hot partitions.
- I did not mention composite partitions it could also help to make more distributed partitions. We decided to move on with a simpler approach but you should be aware of this solution.
- After 1000 partitions your database may perform even worse than without them. So try to select the appropriate partition key or add a data retention policy.
Thanks for reading, I hope it helped you to become a better PostGre dev❤️


































